Deployments Management UI
Deployments management
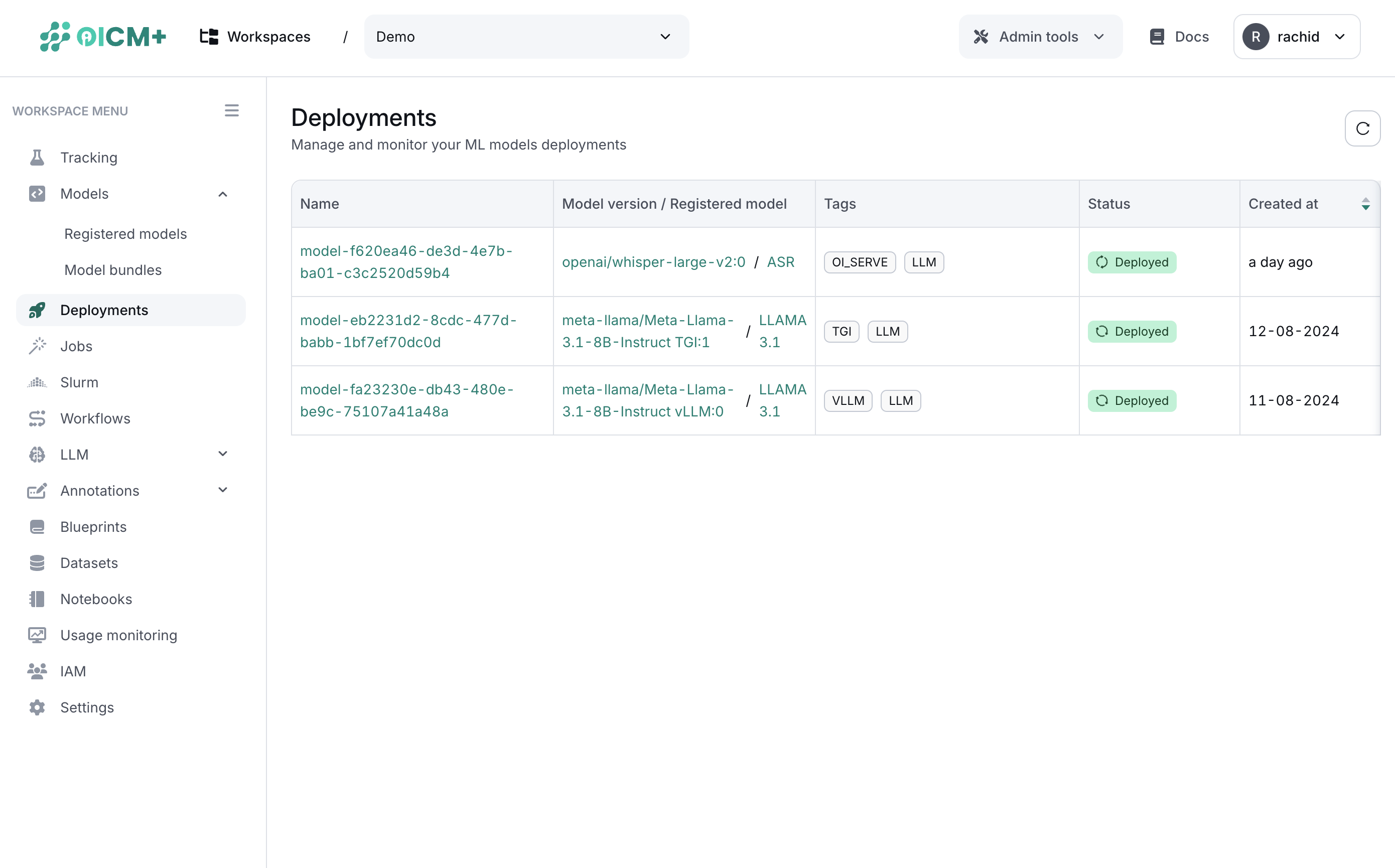
The deployment management UI provides a list of all the deployed models and their versions. The UI provides the following information:
- Model name
- Model version
- Tags (Model Framework, serving framework, etc.)
- Creation date
Deployment details
The deployment details page provides a set of actions that can be performed on the deployed model. The actions include:
- Inference testing
- Logs monitoring
- Infrastructure events monitoring
- Undeploying the model
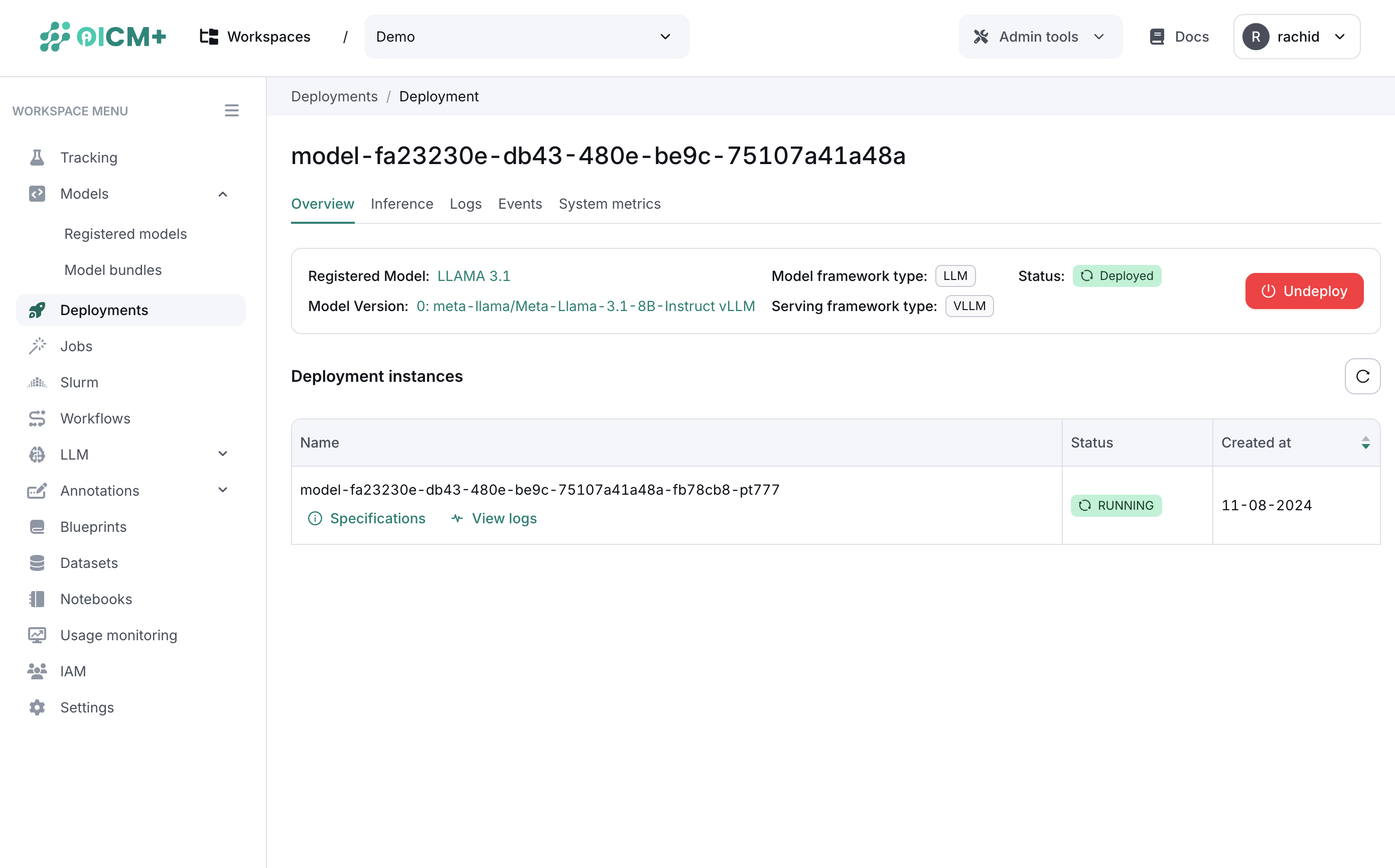
This page also provides the following information in the overview section:
- Model name
- Model version
- List of instances deployed
- Model framework type
- Serving framework type
Inference testing
As a data scientist, you can test the deployed model using the inference testing feature. The inference testing feature allows you to test the model with a set of input data and verify the output.
Let's take an example of an LLM model. You might want to test the model with a set of input data to verify the output while updating the parameters related to an LLM model.
The correspondant UI is shown in the platform as follows:
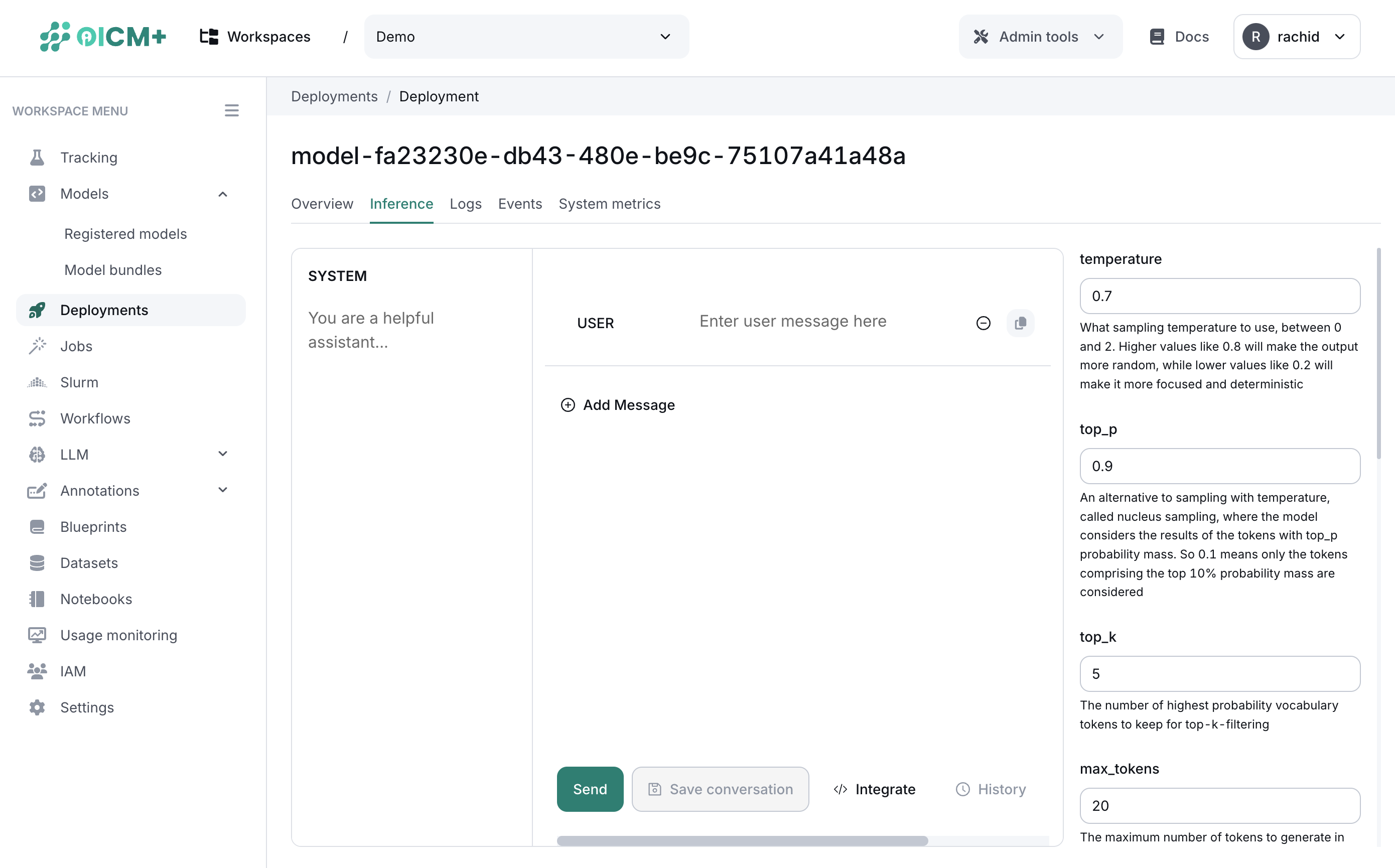
Worth noting that for LLM models, we track each inference response metrics like latency, throughput, and TTFT (time to first token) to provide a better understanding of the model performance.
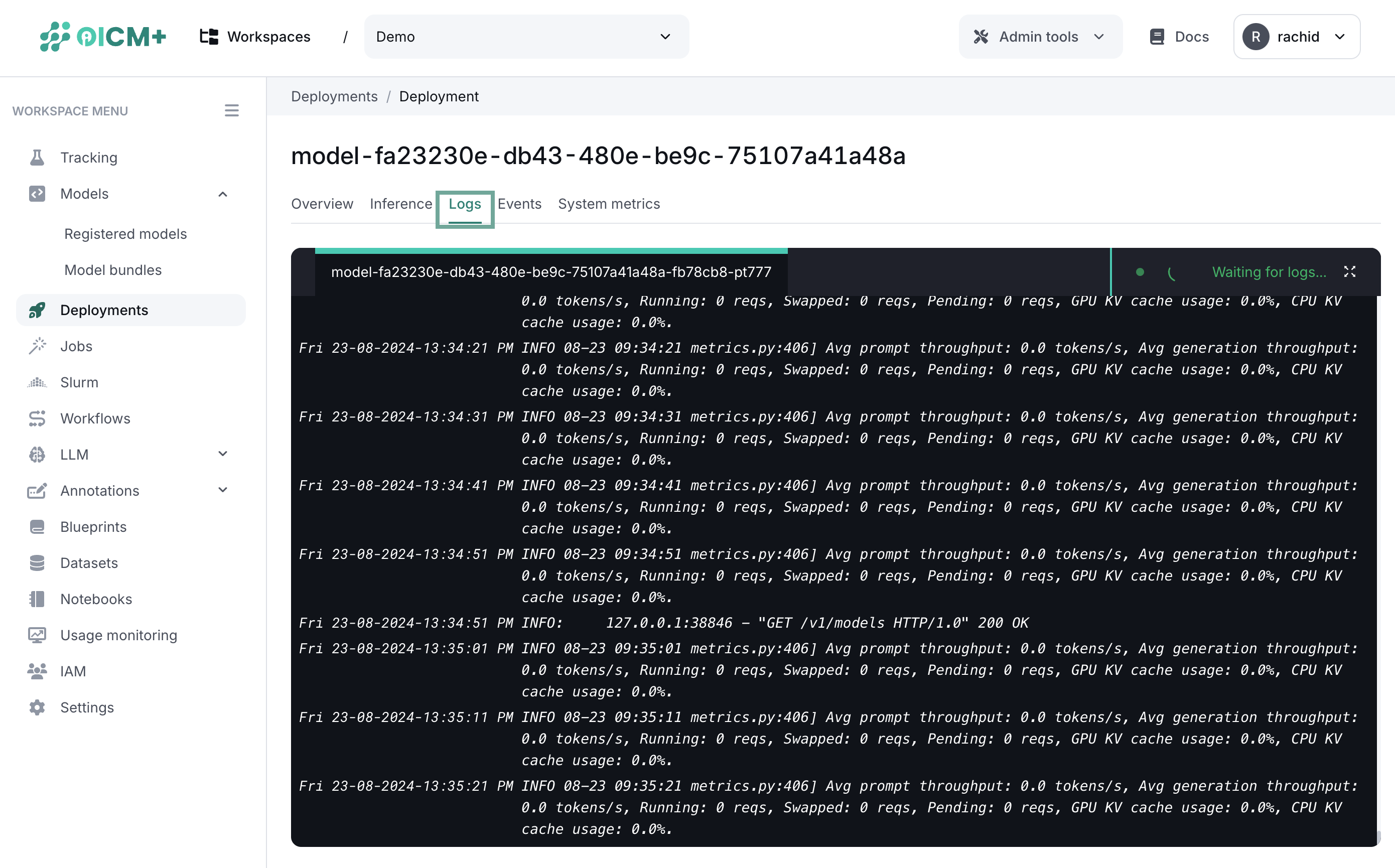
Logs monitoring
The logs monitoring feature allows you to monitor the logs generated by the deployed model. The logs can be used to debug the model and understand the model performance.
The logs monitoring UI is shown in the platform as follows:
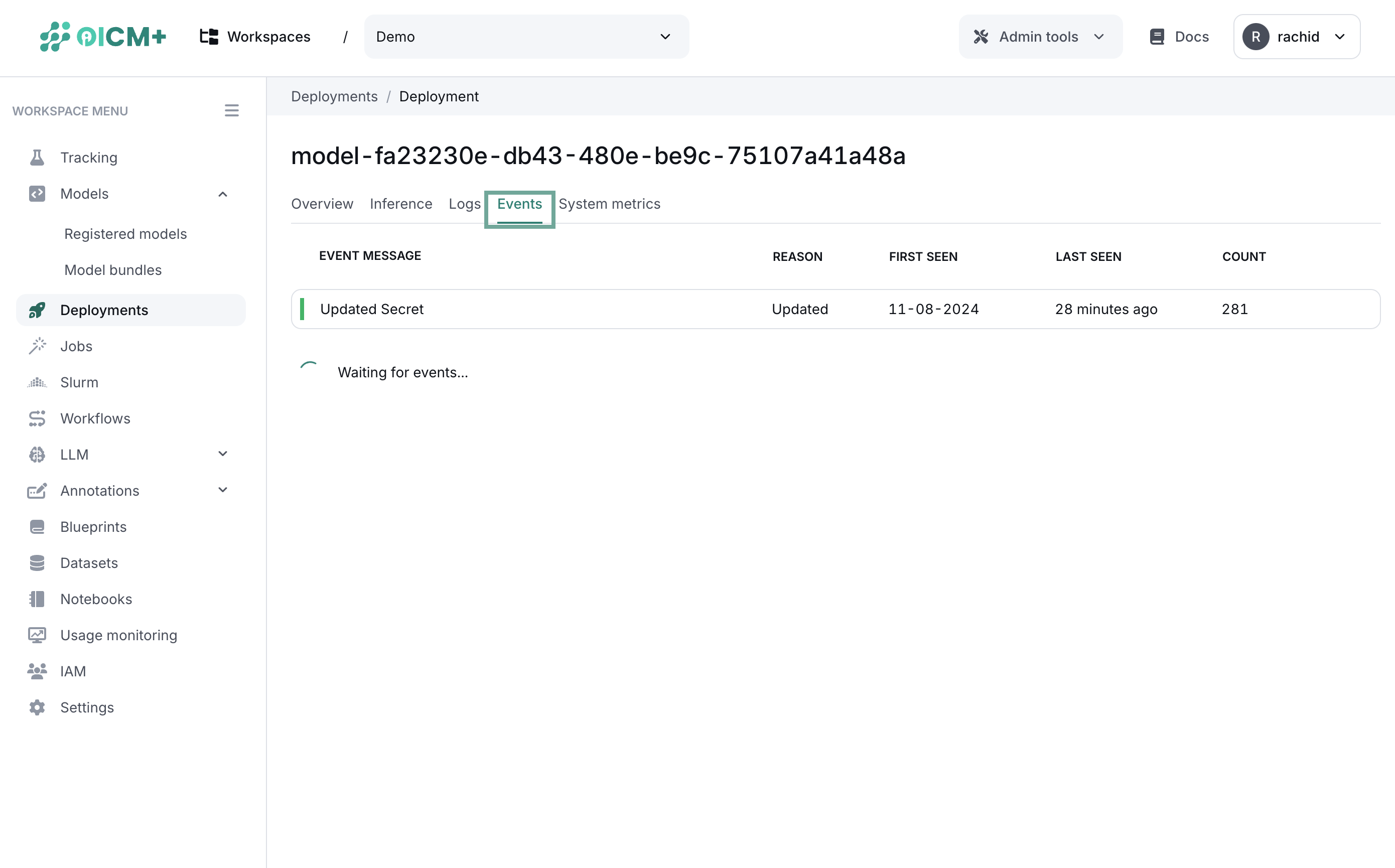
Infrastructure events monitoring
The infrastructure events monitoring feature allows you to monitor the infrastructure events generated while deploying the model. The infrastructure events can be used to understand the infrastructure steps and the time taken to deploy the model.
The infrastructure events monitoring UI is shown in the platform as follows:
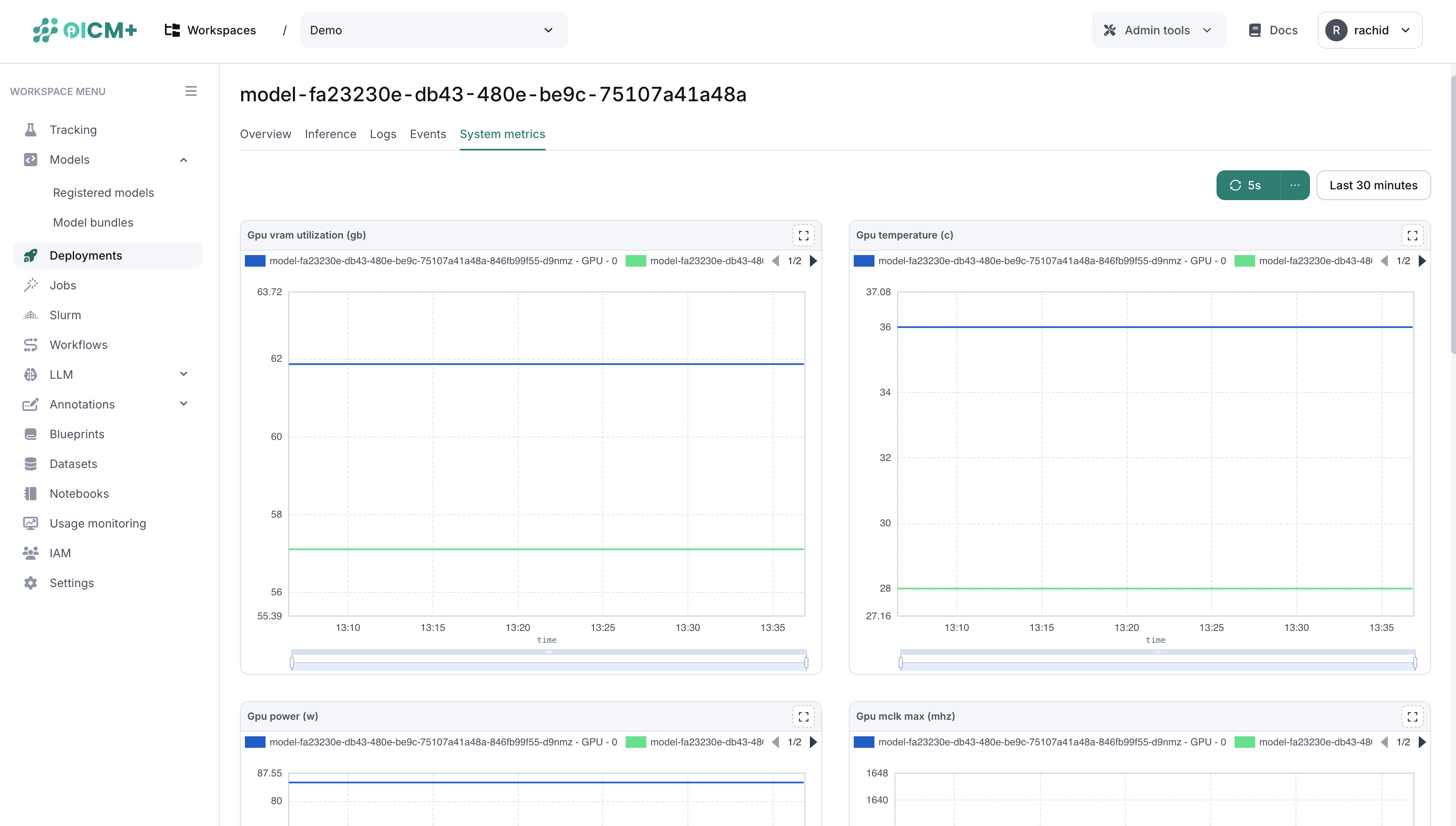
System Metrics Monitoring
The system metrics monitoring feature enables you to track and analyze key performance indicators of your models, specifically focusing on GPU-related metrics. This feature provides real-time insights into GPU VRAM utilization, GPU temperature, and other system metrics.
The system metrics monitoring UI is shown in the platform as follows:
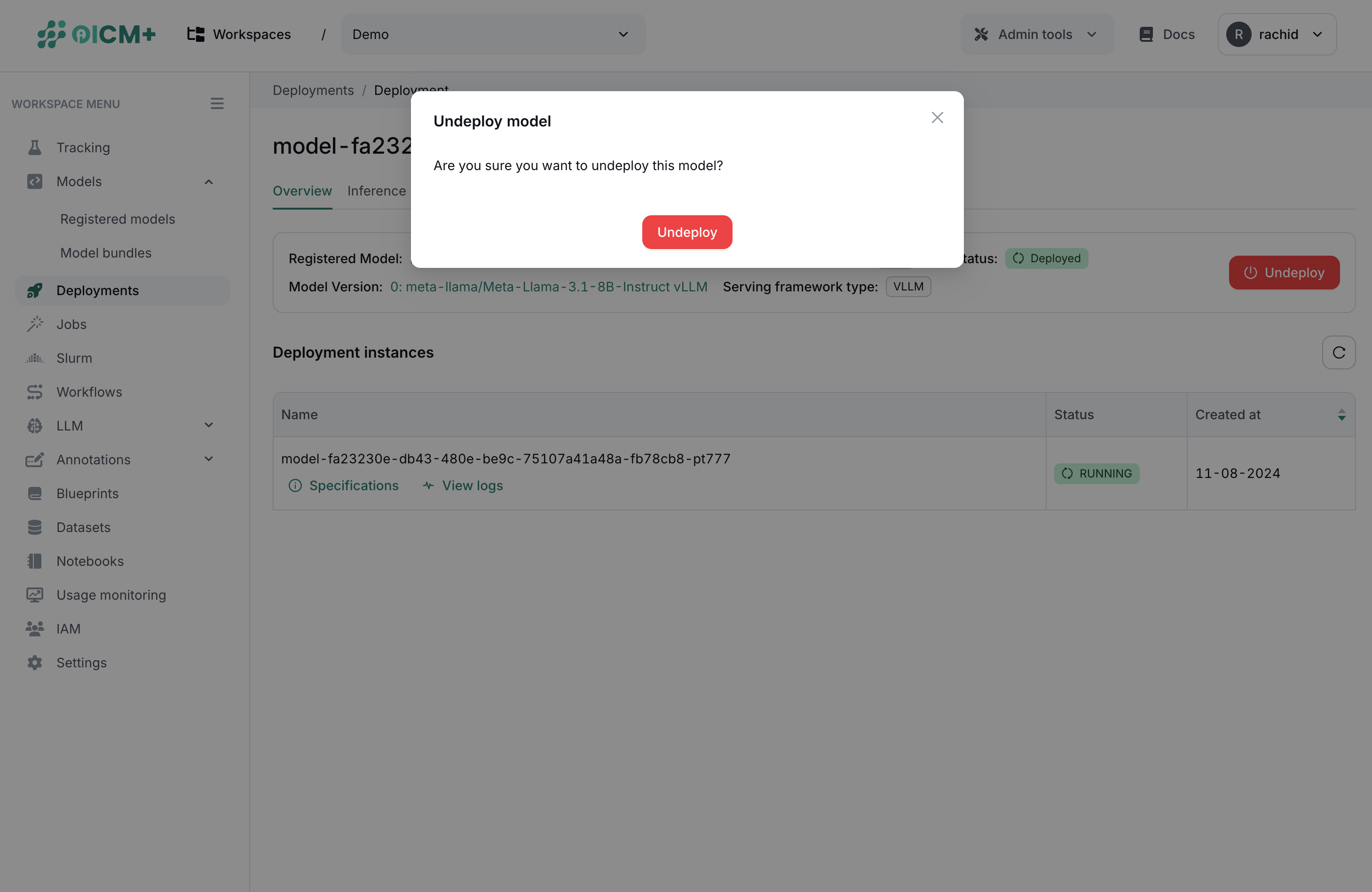
Undeploying the model
The undeploying feature allows you to undeploy the model from the staging/production environment. The undeploying feature can be used to remove the model from the environment and free up the resources.
The undeploying UI is shown in the platform as follows:
Security Scanning
When a model is deployed with stage Production it is automatically scanned for vulnerabilities.
The deployment is not performed if vulnerabilities are found in the model.
Vulnerability scanning is enabled only for source Custom Docker Image and scans for problems in the Docker image.
Deployment examples
In the Deployment module, users can explore various scenarios and best practices for deploying models within our platform. This section provides detailed guidance on how to effectively deploy models after registering them, ensuring that users can maximize the performance and efficiency of their deployments.
Example 1: Deploying LLama 3.1
As mentioned in the Registered Models section, the model of interest should be registered first.
The following instructions provide necessary steps to fill the model configuration fields:
Name: Llama 3.1
Model source (drop down selection): Model Repo
Source (drop down selection): HF
Model Source: meta-llama/Meta-Llama-3.1-8B
Secrets Blueprint: See how to use it here
Model Server: vLLM
Is Chat Model: Toggled On
Use GPU: Toggled off
Accelerator: L4
Memory: 16GB
Storage: 30GB
Once model configurations are saved, it's necessary step to move the model to staging or Production in the actions tab. Also, for reproducibility, user can also save the model as blueprint such that the same procedure can be repeated with the same configurations.
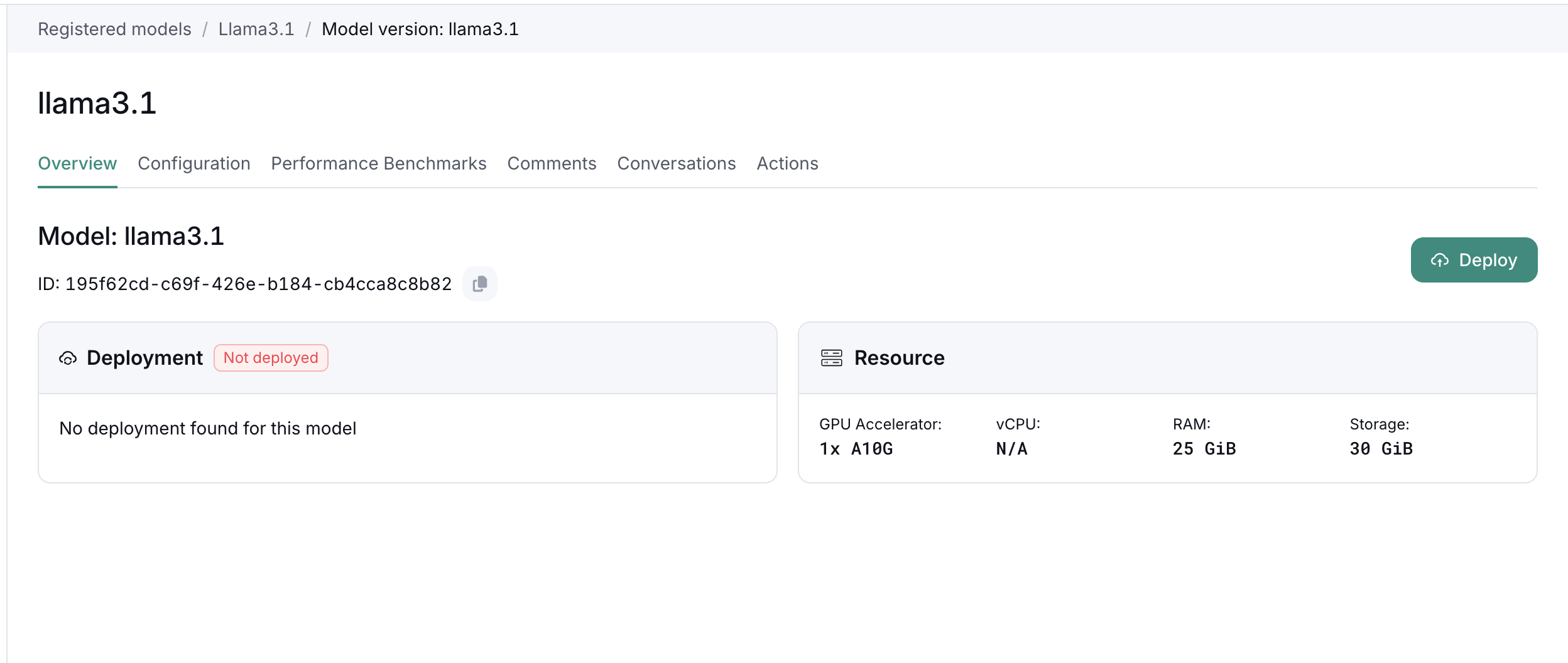
When all the model configurations are set correct, and the stage is "staging" or "production", the deploy button in the model version will be available. By pressing the "Deploy" button, the deployment will be initialized. The deployment window on the left side will enable the hyperlink to the deployment page where the Overview, inference window, Logs, Events and System metrics are available. This way, the developer can monitor the state of the deployment, and observe the logs and events.
Example 2: Deploying Mistral 7B
As in the previous example for deploying LLama 3.1, the Mistral 7B model should also be registered first. Once registered, you can proceed with the following configuration:
Name: Mistral 7B
Model source (drop down selection): Model Repo
Source (drop down selection): HF
Model Source: mistralai/Mistral-7B-Instruct-v0.1
Secrets Blueprint: Refer to the secrets blueprint documentation for details.
Model Server: vLLM
Is Chat Model: Toggled Off
Use GPU: Toggled on
Accelerator: L4
Memory: 16GB
Storage: 30GB
Once the model configurations are saved, you can follow the same steps as in the LLama 3.1 example to move the model to staging, save it as a blueprint if needed, and deploy it. Monitoring and logs can be accessed through the deployment window.
Example 3: Deploying Jais 13B
For deploying the Jais 13B model, the process is similar to that of the LLama 3.1 and Mistral 7B models. Here are the specific configurations:
Name: Jais 13B
Model source (drop down selection): Model Repo
Source (drop down selection): HF
Model Source: inceptionai/jais-13b-chat
Secrets Blueprint: Refer to the secrets blueprints documentation for details.
Model Server: vLLM
Is Chat Model: Toggled On
Use GPU: Toggled On
Accelerator: L4
Memory: 16GB
Storage: 30GB
As with the other examples, once the model configurations are set, move the model to staging, save it as a blueprint if required, and deploy it. All deployment actions, monitoring, and logs can be accessed similarly through the deployment window.
Additional Considerations
When deploying models, there are several key aspects to keep in mind to ensure a smooth and effective process:
1. "Is Chat" Toggle
- Models can be designed for various tasks such as instruct, chat, or other downstream tasks. It’s crucial to correctly toggle the "Is Chat" option based on the model’s intended purpose. If the model is specifically designed for chat interactions, ensure that the "Is Chat" toggle is enabled. For other tasks, leave it disabled to avoid misconfiguration.
2. Setting Correct Blueprints
- For models gated by HuggingFace (HF), ensure that the secret blueprint is correctly configured. The owner of the secret blueprint should have the necessary access permissions granted on HuggingFace. Additionally, make sure that the terms of service for the model are accepted in the associated HF account to prevent deployment issues.
3. Monitoring Activity Logs
- The platform provides an "Activity Logging" tab on the model overview page, where you can track deployment actions. This log includes details on who deployed the model and at what time. Regularly monitoring these logs is essential for maintaining accountability and understanding the deployment timeline.
By paying attention to these considerations, you can avoid common pitfalls and ensure that your model deployments are handled efficiently and securely.