LoRA Adapters
As part of the fine-tuning features, we support LoRA adapters in the platform. LoRA drastically reduces the number of trainable parameters needed to adapt a large language model to a new task or domain, making fine-tuning faster, more efficient, and less resource-intensive.
Fundamentals
LoRA, or Low-Rank Adaptation, is a groundbreaking technique that revolutionizes how we fine-tune large language models (LLMs). Traditionally, fine-tuning an LLM involved updating all of its parameters, which could be computationally expensive and time-consuming. LoRA takes a different approach by freezing the pre-trained model weights and introducing small, task-specific adapter modules.
These adapter modules contain a reduced number of trainable parameters, typically a fraction of the original model size. During fine-tuning, only these adapter parameters are updated, significantly reducing the computational overhead and enabling efficient adaptation to new tasks or domains. The result is a fine-tuned LLM that retains the knowledge and capabilities of the base model while being tailored to specific requirements.
LoRA in practice
To leverage the power of LoRA for efficient fine-tuning, simply toggle the "LoRA" option within the Training section of your fine-tuning configuration. This will activate LoRA adapters during the fine-tuning process, allowing you to train your model more effectively while minimizing computational resources.
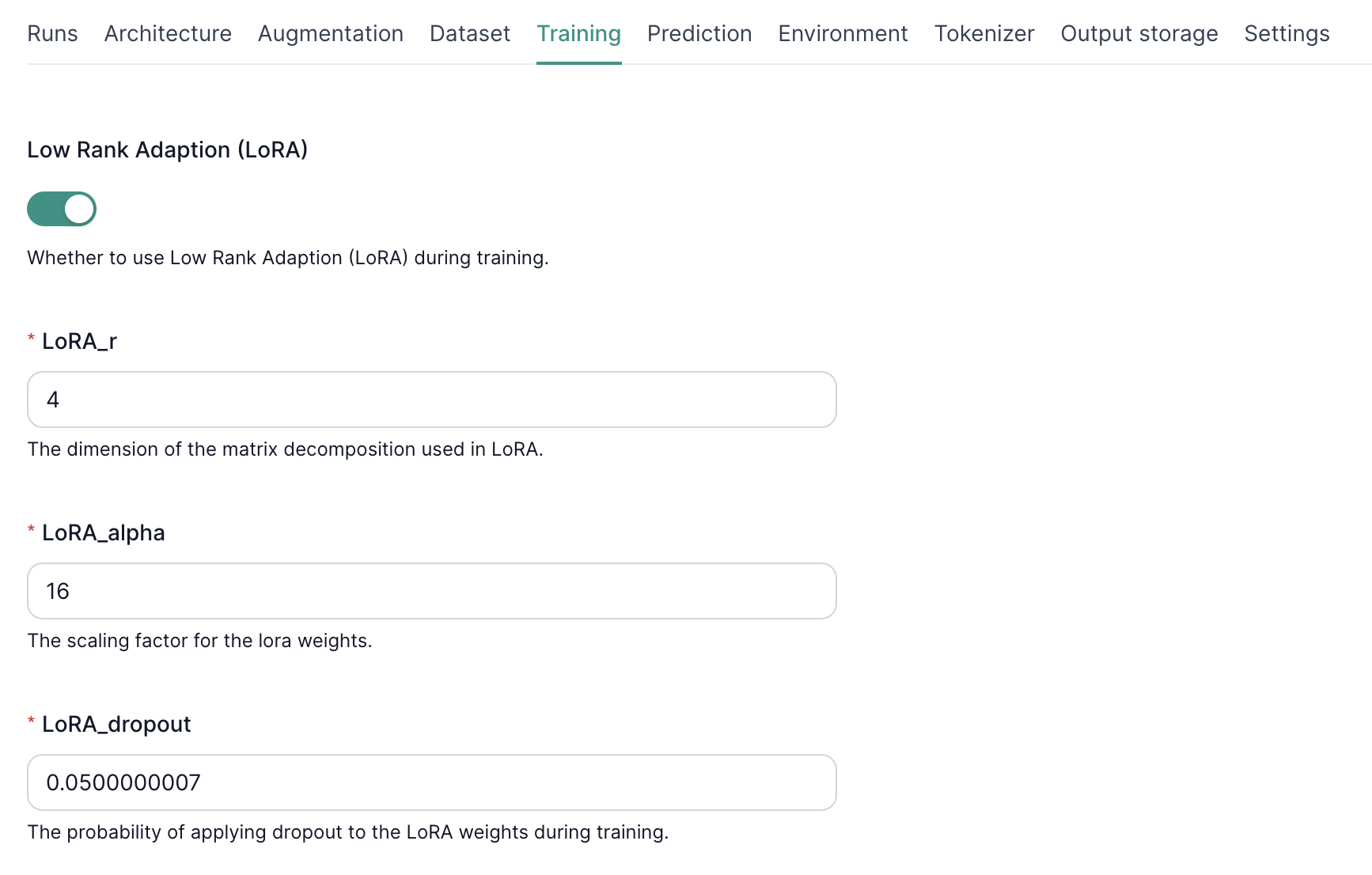
Configuring LoRA Hyperparameters
Once LoRA is enabled, you can further customize its behavior by adjusting the following hyperparameters:
- LoRA_r: This parameter controls the rank of the low-rank matrices used in the adapter modules. Higher values of lora_r increase the model's capacity to learn new information but may also lead to overfitting. Experiment with different values to find the optimal balance for your specific task.
- LoRA Alpha: The alpha hyperparameter scales the updates applied to the adapter weights during training. A higher lora_alpha results in more aggressive updates, while a lower value promotes more conservative learning.
- LoRA Dropout: Dropout is a regularization technique that helps prevent overfitting by randomly dropping out a fraction of the adapter weights during training. The lora_dropout parameter controls the probability of applying dropout.
By fine-tuning these hyperparameters, you can optimize the performance of LoRA adapters for your specific task and dataset.
Storing LoRA weights after fine-tuning
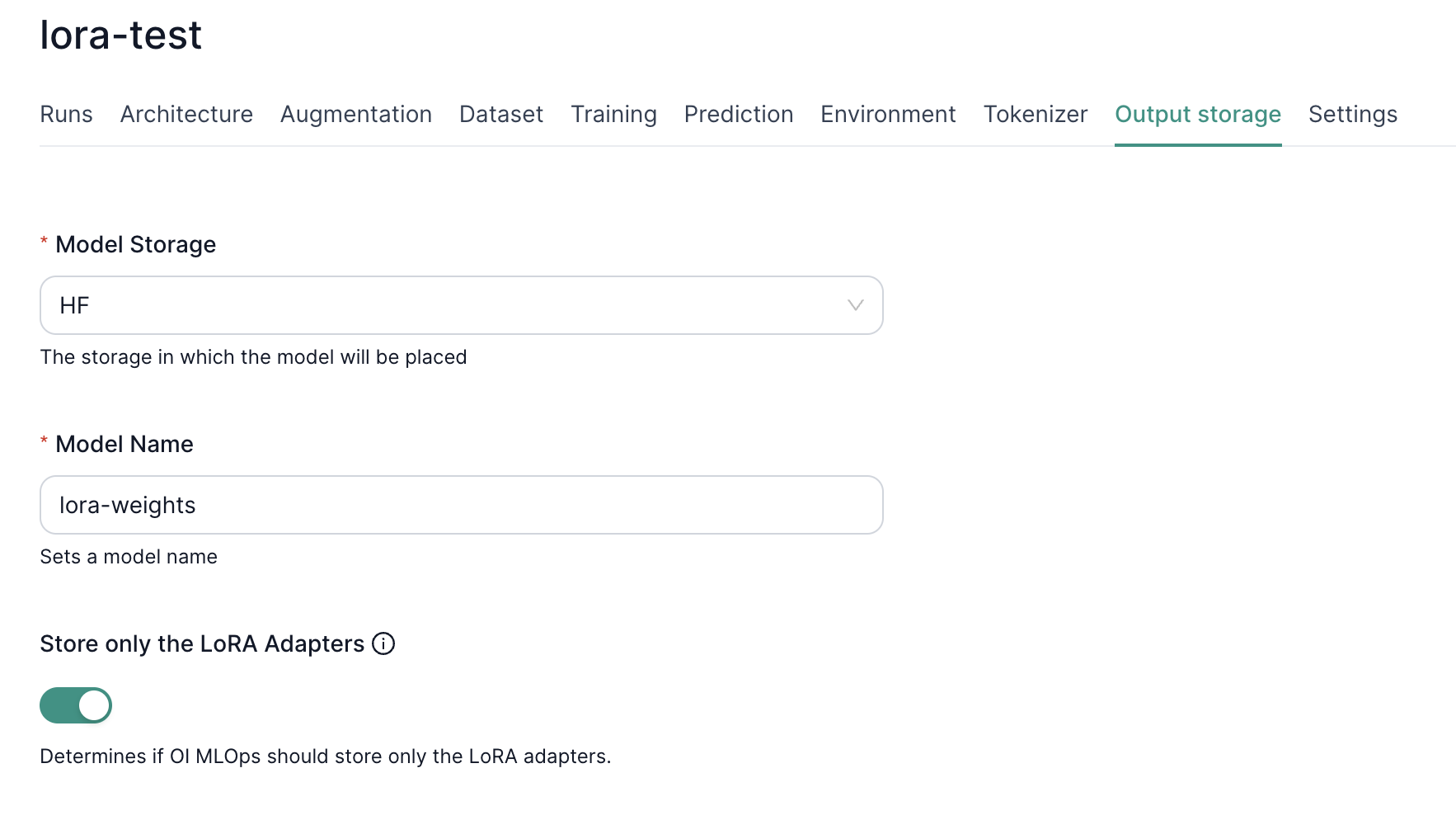
A key advantage of LoRA adapters is their small size compared to full fine-tuned models. To leverage this, our platform allows you to store only the trained LoRA adapter weights in your specified output storage. This significantly reduces storage costs and simplifies model deployment, as you only need to retain the original base model and the compact LoRA adapters.
To activate this feature, simply toggle the "Store only the LoRA Adapters" option in the Output storage bar of the fine-tuning configuration. This will instruct the platform to save only the LoRA adapter weights upon completion of training, excluding the full model parameters.
Deployment with LoRA Adapters
When deploying your model, you can easily load the base model and the relevant LoRA adapter weights to create a fine-tuned model tailored to your specific task. This approach offers a streamlined and efficient workflow for managing and deploying customized language models.
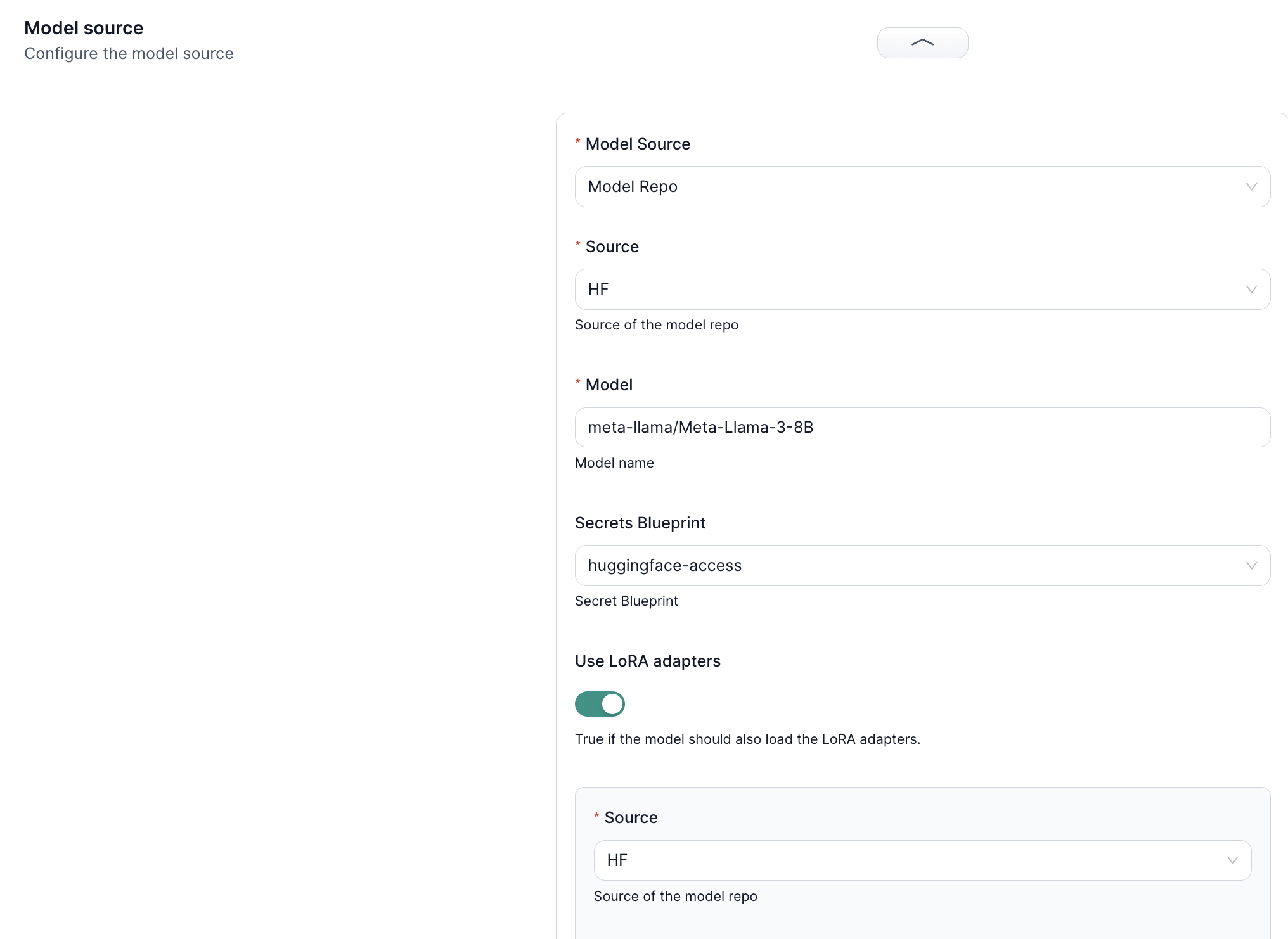
While deploying the model, choose the source for baseline model, and toggle "Use LoRA Adapters" option, and specify the previously stored LoRA Weights. Currently supported both HuggingFace and S3, the platform allows to deploy model with the combination of baseline LLM and lightweight LoRA. This facilitates the memory-efficient experimentation.
Knowledge Benchmarks with LoRA
To assess the performance of your fine-tuned model on specific knowledge domains or tasks using custom benchmarks, you can leverage LoRA adapters in the following way:
First, load Base Model and LoRA Weights: Start by specifying the original language model. Choose the source between S3 and HuggingFace, provide valid credentials if the access is gated. Then, specify the source of your pre-trained LoRA adapter weights, which encapsulate the fine-tuned knowledge for your desired domain, following the same way, .
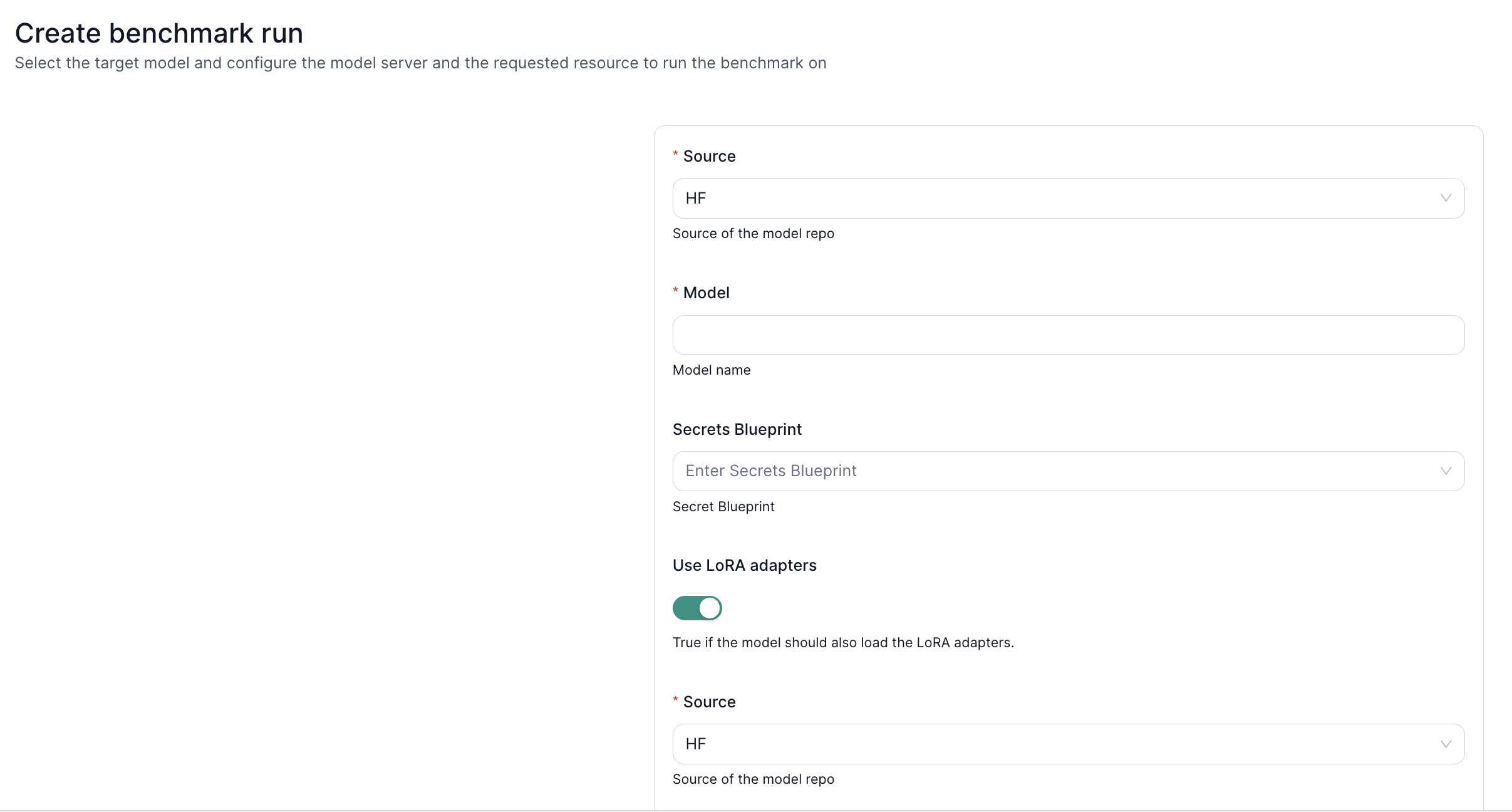
Make sure to check the validity of the credentials in the secrets blueprint. To run the knowledge benchmarks with LoRA, you need to have the read access to the specified baseline model, as well as the LoRA weights through the access keys provided in the configuration.