Fine Tuning
Llama fine tuning
This examples fine-tunes Llama 2 on a Q&A list.
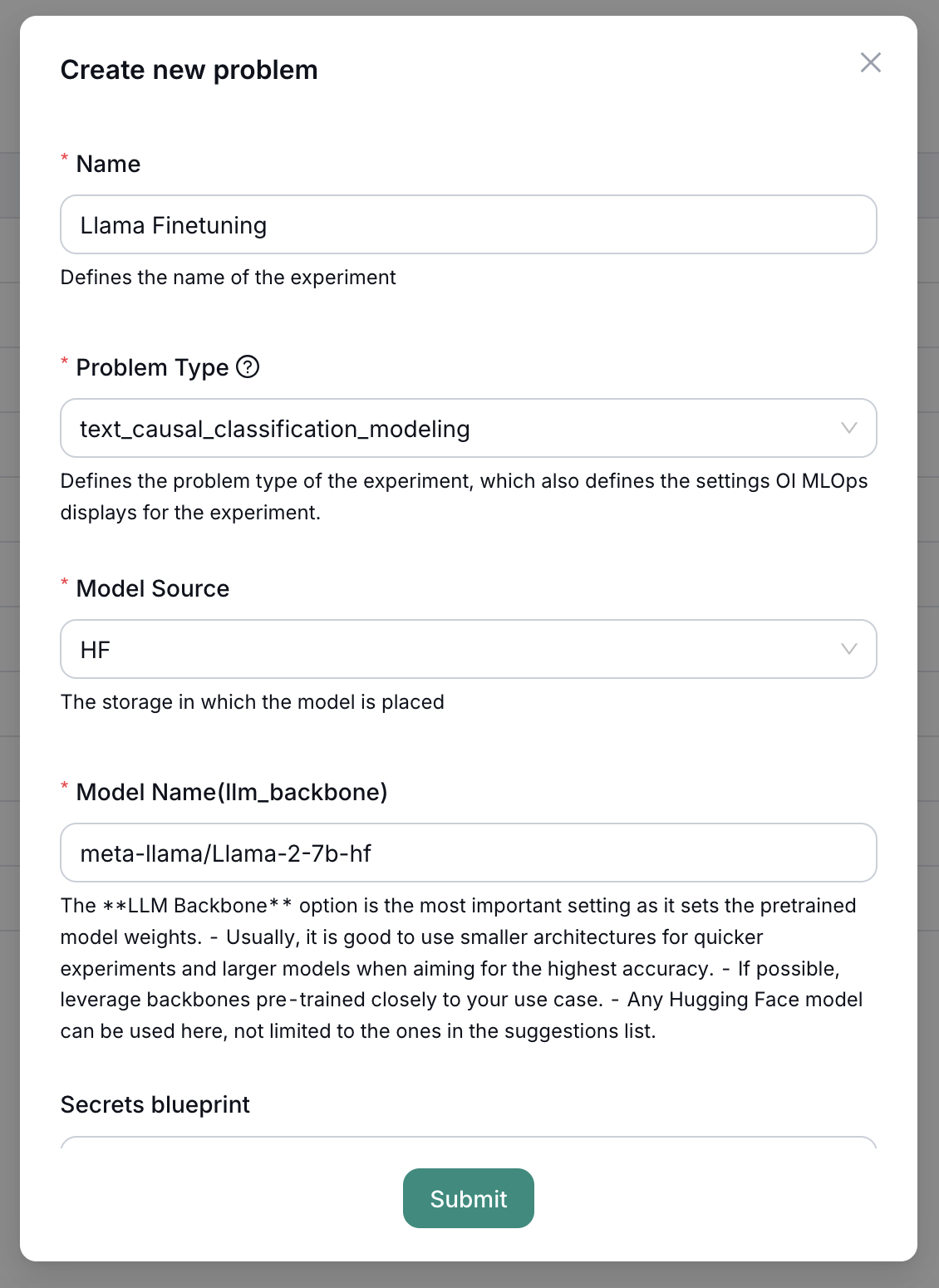
Problem
- Name:
Llama Finetuning - Problem Type:
text_causal_classification_modeling - Model Source:
HF - Model Name:
meta-llama/Llama-2-7b-hf - Secrets Blueprint:
HF Meta- A token with access to meta-llama/Llama-2-7b-hf
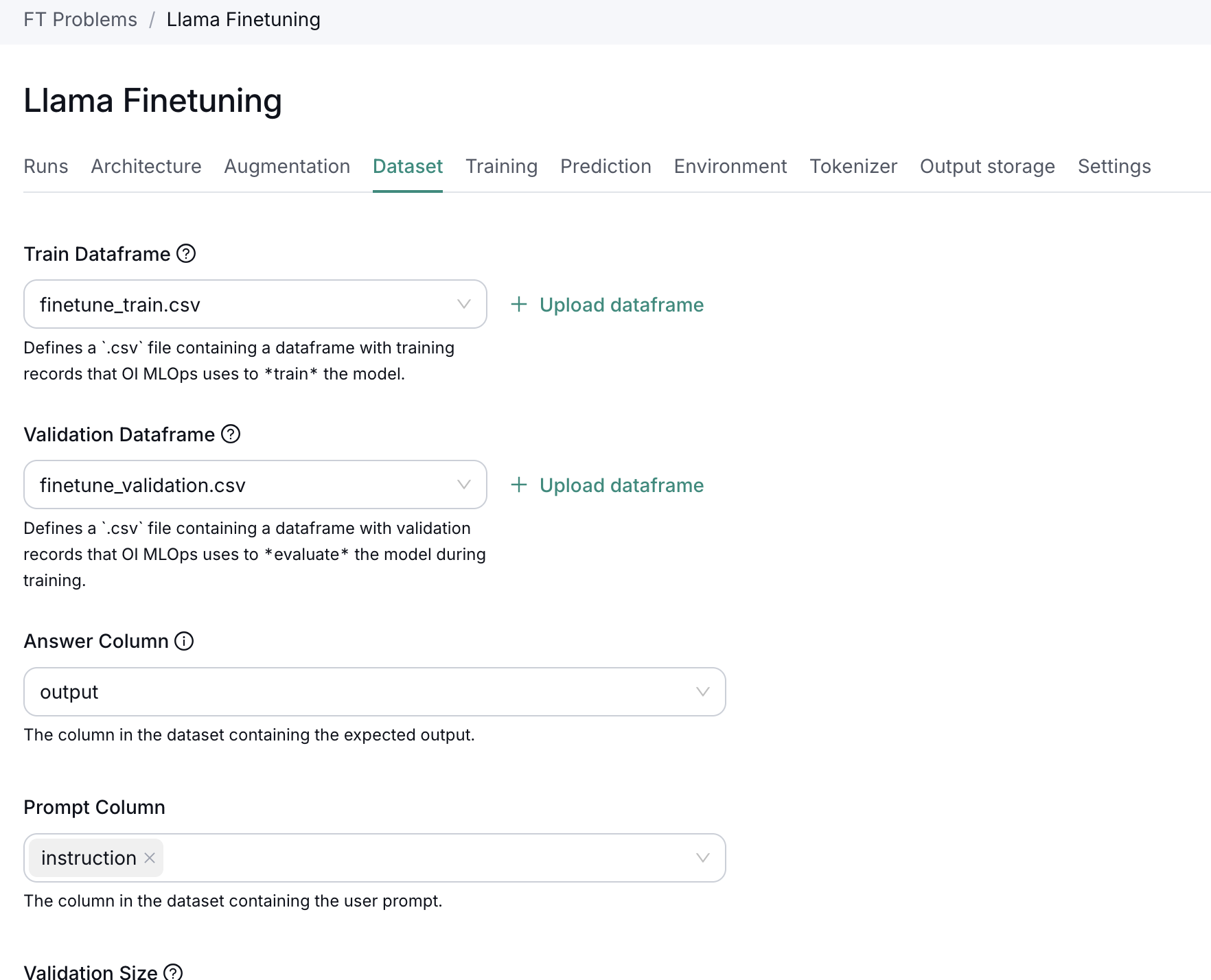
Dataset
- Train dataframe: finetune_train.csv
- Validation dataframe: finetune_validation.csv
- Answer column:
output - Prompt column:
instruction - Validation size: 0.01
Output storage
- Model Storage:
HF - Model Name:
llama-finetuned - Store only the LoRA Adapters:
true - Secrets Blueprint:
Write Token- A token with write access to HF
Run
- Run Title:
Run 01 - Resources
- Accelerator:
A10G - GPU Count:
1 - Memory:
64
- Accelerator:
- Tracking
- Experiment name:
Llama Finetuning - API key: API key generated from User > API Keys dropdown
- Tracking mode:
after_epoch
- Experiment name: