Model Bundles
Model bundles are containers for your model artifacts, essential for deploying models trained outside the OICM+ platform. For examples of how to configure model bundles using common ML libraries, check Github Examples.
Model Bundles Overview
When you select a model bundle, you will be redirected to the overview page. Here, you can upload your inference code or any necessary artifacts, such as pickle files, training scripts and requirements.txt files.
Model Bundles Settings
To update or delete the model bundle, navigate to the Settings tab.
Model Bundle Files
This section describes the files needed to create a model bundle.
A model bundle contains all the files need to
-
configure the environment (Environment Configuration)
-
run the model (Model Code)
For a list of examples using the most common ML libraries check Github.
Environment Configuration
The environment configuration is contained in the model server configuration under the model version settings.
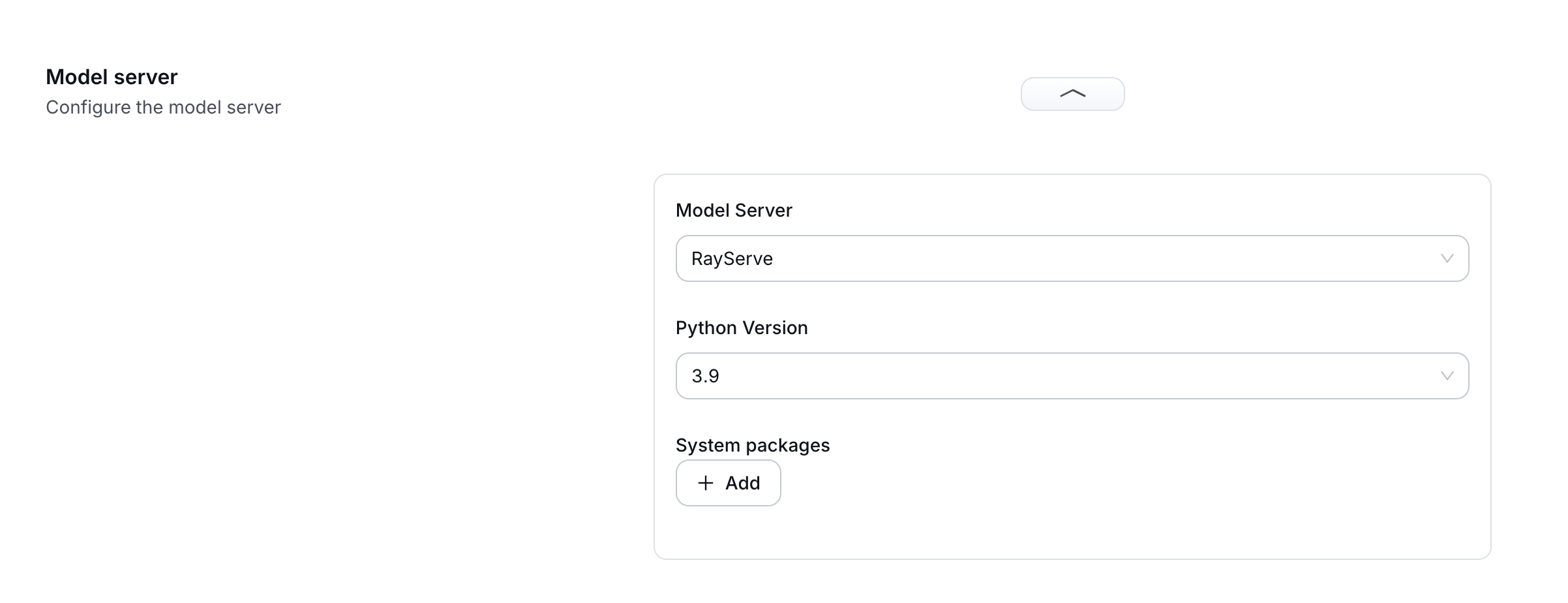
In the model server configuration, the user can set the following fields:
-
model server: RayServe is the only supported model server for model bundles. -
python_version: Python version. Possible values arepy39,py310,py311. -
system packages: list of system packages to install before starting the deployment.
Requirements
The requirements are contained in the requirements.txt file and should be placed in the root of the model bundle.
Model Code
The model application code is contained in model/model.py.
The file must contain a class named Model with methods load and predict.
class Model:
def __init__(self, **kwargs) -> None:
...
def load(self) -> None:
# Load the model
...
def predict(self, model_input: Any) -> Any:
# Apply the model from the input received from the REST endpoint
...
return model_output
The bundle can contain other files needed by the model (e.g. weights) in the data folder.
Example
In this example we create a bundle to deploy a scikit-learn model.
We create the files
config.yaml
The config.yaml sets the environment to Python 3.9.
requirements.txt
The requirements.txt file contains the requirements for the model
model.py
We load the model from the .pkl file and then use that model for predictions.
from typing import Any
import os
import numpy as np
import pickle
import logging
class Model:
def __init__(self, **kwargs) -> None:
self._data_dir = kwargs["data_dir"]
config = kwargs["config"]
model_metadata = config["model_metadata"]
self._model_binary_dir = model_metadata["model_binary_dir"]
self._model = None
def load(self) -> None:
model_binary_dir_path = os.path.join(
str(self._data_dir), str(self._model_binary_dir)
)
pkl_filepath = os.path.join(model_binary_dir_path, "data", "model.pkl")
logging.info(f"Loading model file {pkl_filepath}")
with open(pkl_filepath, "rb") as hand:
self._model = pickle.load(hand)
def predict(self, model_input: Any) -> Any:
inputs = np.asarray(model_input) # Convert the input to numpy array
result = self._model.predict(inputs)
predictions = result.tolist() # Convert the model output to a Python list
return {"predictions": predictions}