Model Hub
The Model Hub provides a curated collection of pre-configured AI models that are onboarded to your OICM+ environment based on your specific use cases and hardware capacity. These models come with optimized configurations, allowing you to deploy production-ready AI models with minimal setup.
Quick Deployment from Model Hub
Browsing Available Models
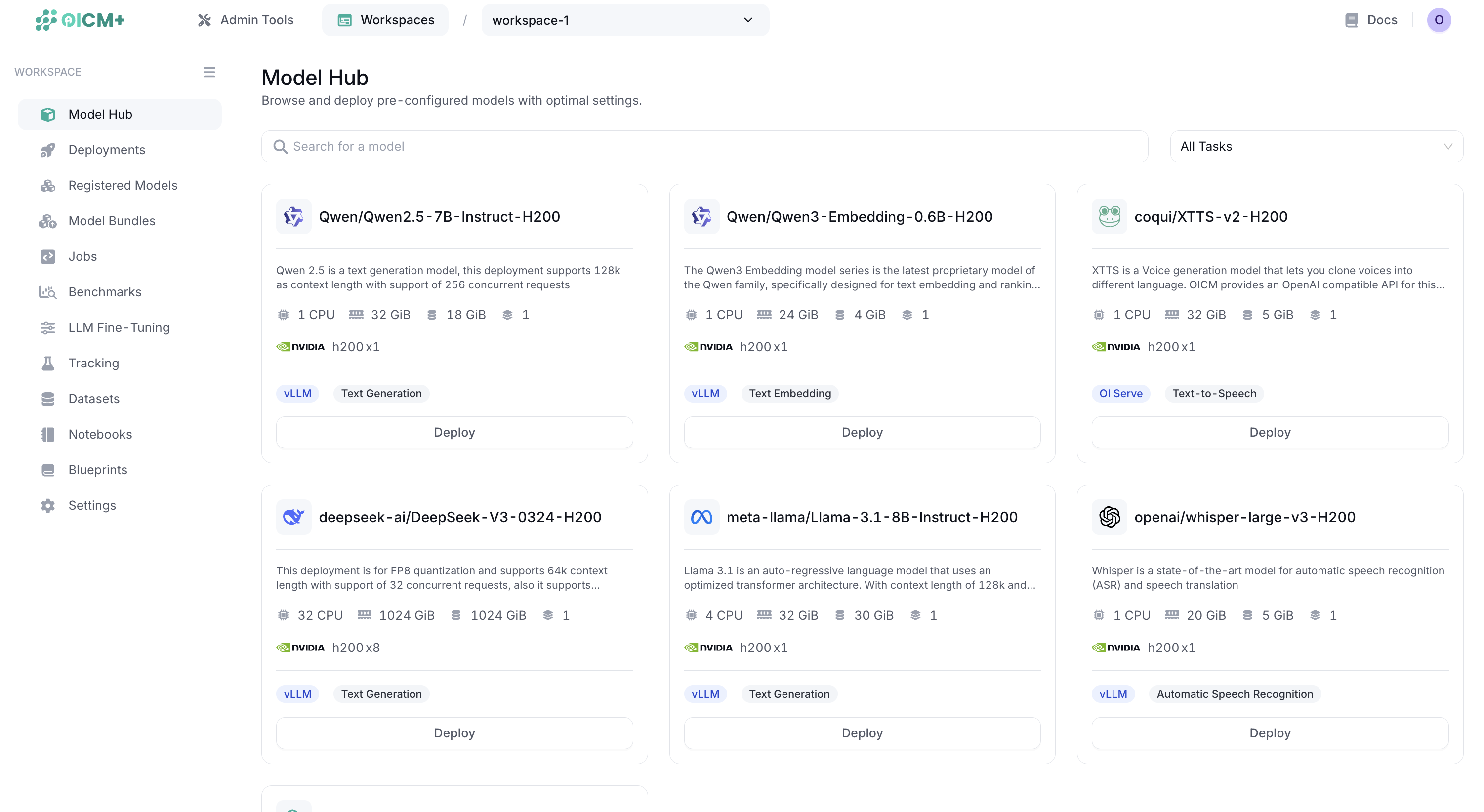
The Model Hub displays all available pre-configured models in a card-based layout. Each model card shows:
- Model name and description
- Resource requirements (CPU, RAM, Storage)
- Hardware specifications (GPU type and count)
- Task type and serving framework
- One-click Deploy button
One-Click Deployment
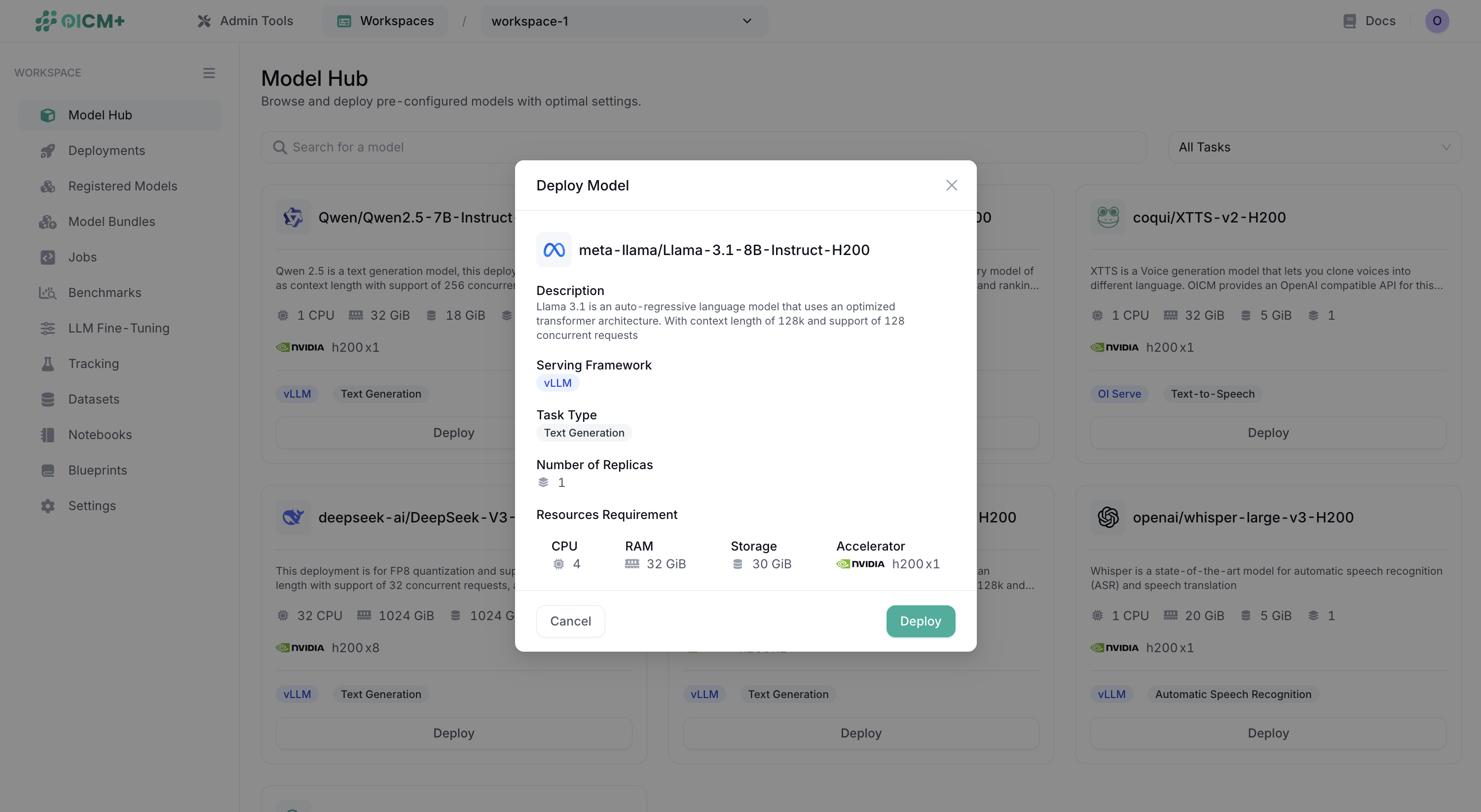
For immediate deployment with default settings:
- Click the Deploy button on any model card
- Review the deployment summary in the modal dialog:
- Model description and capabilities
- Serving framework (e.g., vLLM)
- Task type (e.g., Text Generation)
- Number of replicas (default: 1)
- Resource requirements (CPU, RAM, Storage, Accelerator)
- Click Deploy to launch the model with pre-configured settings
Prerequisites: Ensure your workspace has sufficient GPU resources allocated. Deployments will queue until GPU resources become available.
Once you click "Deploy", you will be directed to the deployment overview page.
Custom Configuration Deployment
For advanced users who need to customize deployment settings, start by choosing your deployment source:
- Deploy from Model Hub: Quick-deploy pre-configured models.
- Deploy from Model Registry: Deploy models you have added to your custom registry.
- Deploy from Docker Image: Deploy using a custom Docker image container.
Step-by-Step Configuration Process
When selecting Deploy from Model Hub, follow the multi-step configuration wizard:
Step 1: Model Selection
- Navigate to Deployments → Deploy a Model.
- Select Deploy from Model Hub from the deployment options.
- Browse and select your desired model from the available options.
- Click Next.
Step 2: Resource Allocation
Configure compute resources and scaling behavior for your deployment:
Compute Type Selection:
- GPU (recommended for most AI models)
- Fractioned GPU (for smaller workloads)
- CPU (for lightweight models)
Resource Configuration:
- Memory (GiB): Available RAM allocation
- Storage (GiB): Available storage quota
- Accelerator: GPU type and specifications
- Accelerator Count: Number of GPU units required
Scaling Configuration:
- Enable Autoscaling: Toggle to enable automatic replica scaling.
- Target Metric: Choose scaling metric (e.g.,
ml_model_concurrent_requests). - Scale Threshold: Set the threshold value for scaling decisions.
- Min/Max Replicas: Define the minimum and maximum active instances.
- Activation Threshold: Minimum load before scaling up.
Step 3: Deployment Configuration
Configure how the model will be served:
- Model Server: Choose from available serving frameworks:
- vLLM (recommended for most language models)
- SGLang
- TGI 3
Step 4: Review and Deploy
Review all configured sections. At this stage, you have two options:
- Save: Store your configuration as a template for future use.
- Save & Deploy: Save the configuration and immediately launch the model deployment.
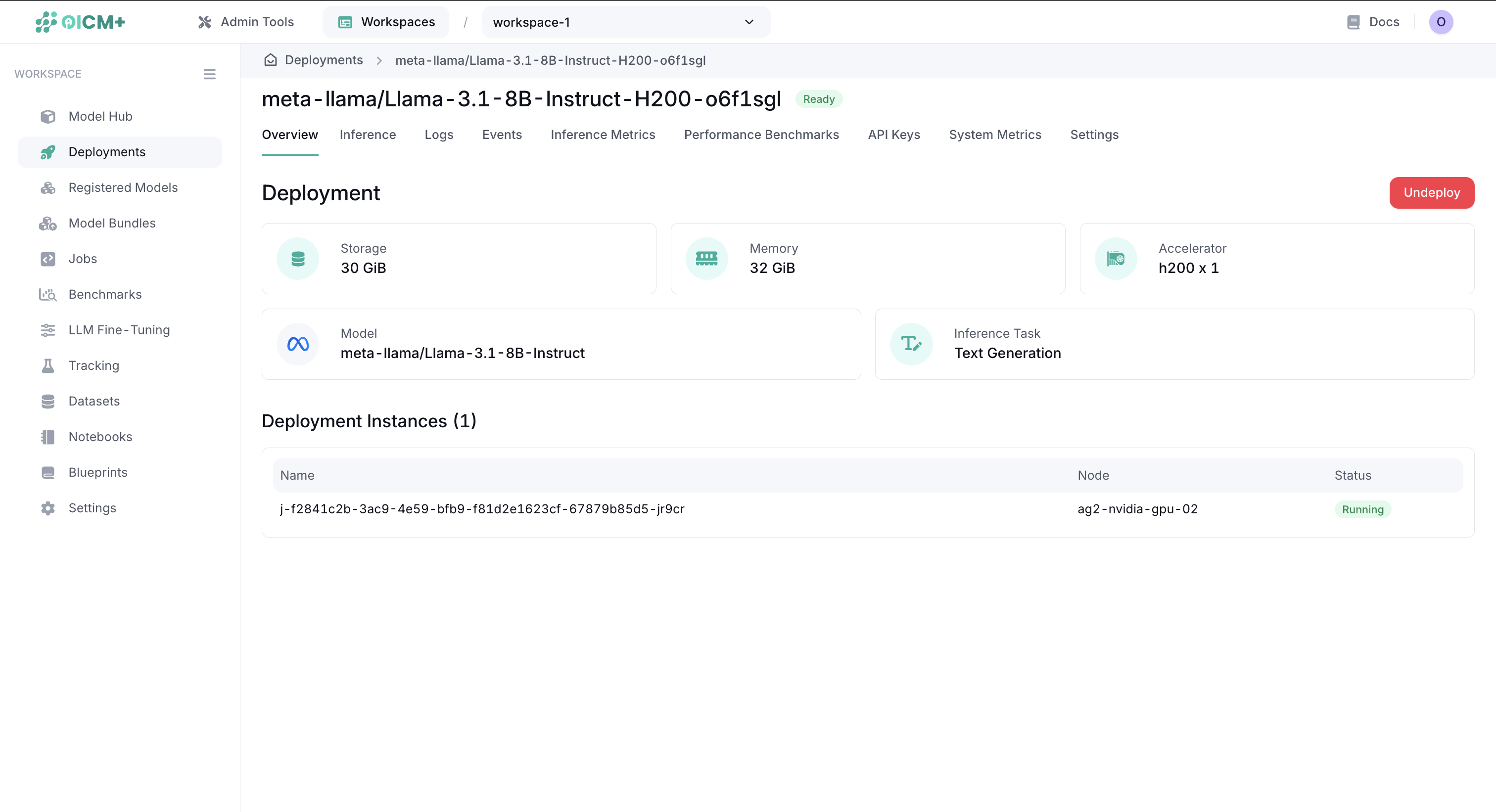
Post-Deployment Management
Monitoring Active Deployments
Once deployed, your model appears in the Deployments section with comprehensive monitoring capabilities. Each deployment displays key information organized in sections:
Model Information:
- Source: Model origin and identifier
- Task Type: Inference task (e.g., Text Generation)
- Serving Framework: Model serving framework (e.g., vLLM)
Resource Allocation:
- GPU Type and Count: Accelerator specifications (e.g., h200 x1)
- Memory (RAM): Allocated memory in GiB
- Storage: Allocated storage in GiB
Instance Status:
- Deployment Instances: Running pod replicas with their names and current status
- Instance Count: Number of active replicas
Deployment Management Options
Depending on the current deployment status, the Undeploy button is available to:
- Queued Deployments: Cancel pending deployments waiting for resources.
- Active Deployments: Terminate running deployments and clean up resources.