Performance Benchmark
Performance benchmarks help you evaluate the scalability and responsiveness of Text Generation and Image-Text-to-Text models under varying user loads. This guide shows how to create, run, and review benchmarks for deployed models that use vLLM, TGI, SGLang, TensorRT or any serving framework used with the supported inference task.
1. Overview
- Applicability – Only supported by Text Generation and Image-Text-to-Text models.
- Goal – Measure how a model performs (latency, throughput, etc.) under simulated real-world concurrency.
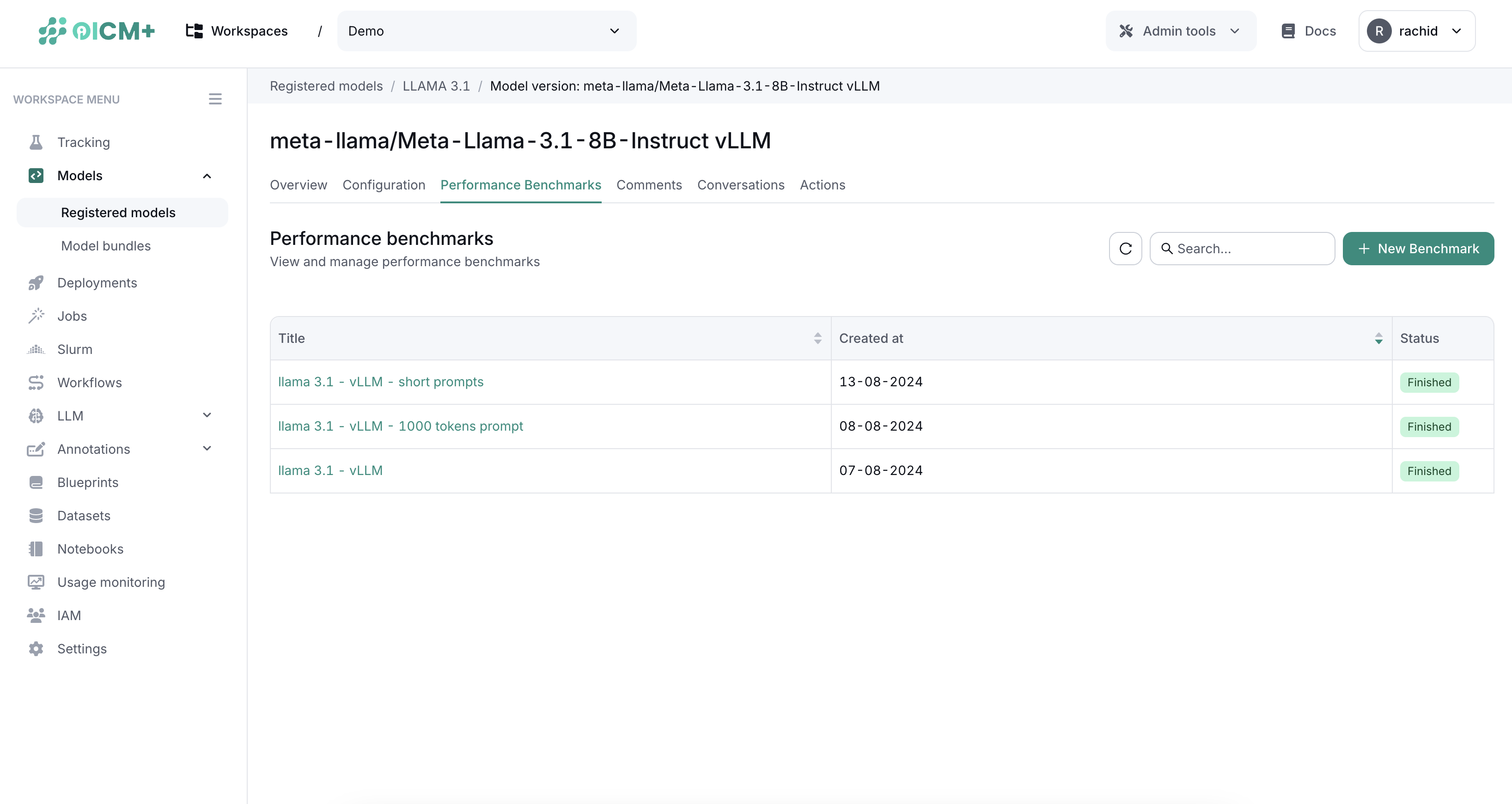
2. Accessing Performance Benchmarks
- Navigate to the Deployment page for the model you want to test.
- Click on the Performance Benchmark tab to see a list of previously run benchmarks.
3. Creating a New Benchmark
- New Benchmark – Click the New Benchmark button.
- Configuration Form – Fill out the form with relevant details:
- Title – Short name for easy identification.
- Number of Concurrent Users – E.g., 50, 100, 200.
- Prompt File – Upload test prompts used during the benchmark.
- Serving Parameters – (Optional) Adjust temperature, top-k, etc.
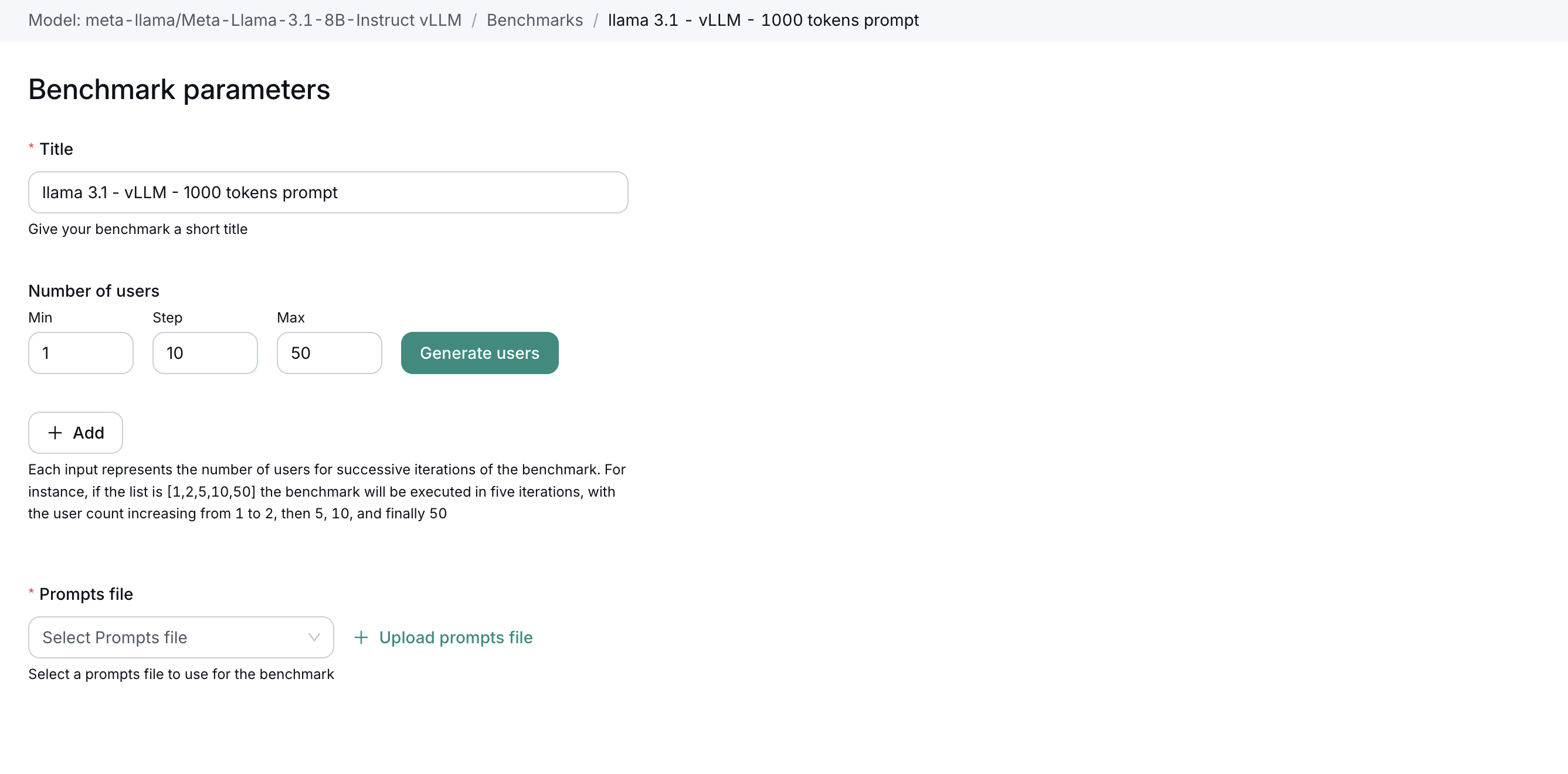
- Save and Run – Launch the benchmark with one click.
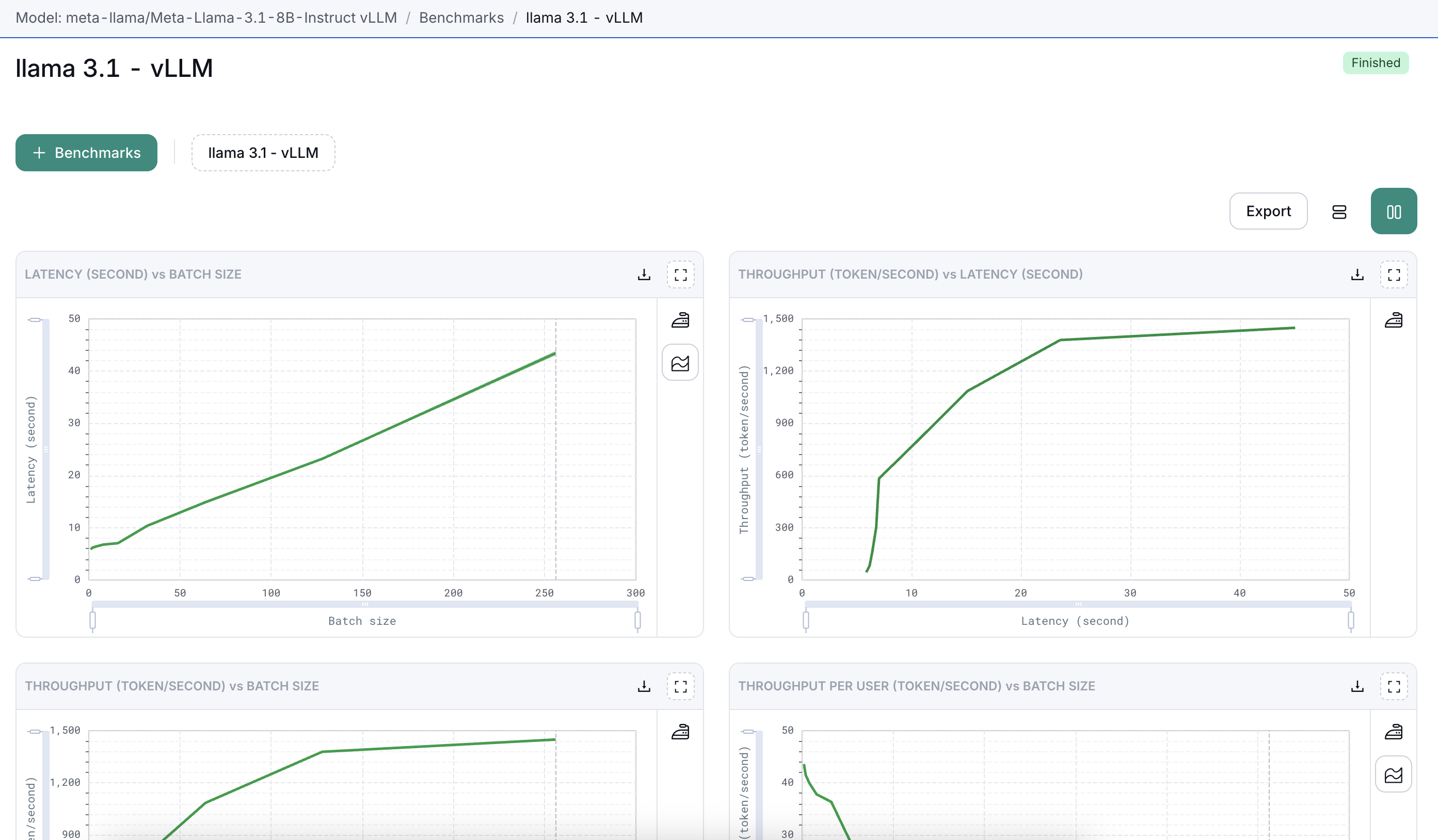
4. Monitoring and Results
- Real-Time Monitoring – View benchmark progress in the Results Dashboard.
- Completion – Results appear automatically once the test finishes.
5. Exporting Results
Export benchmark data for deeper analysis or stakeholder reviews:
- PDF – Create a shareable summary report.
- Excel – Download raw data for detailed analytics.
Use these insights to optimize model settings and enhance overall performance.
Next Steps
- Deployments UI – Learn how to manage and monitor deployed models in production.
- Model Version Configuration – Review best practices for configuring text generation models.
- Registered Models & Versions – Explore how to maintain multiple versions of your text generation models.