Model Version Configuration
Configuring a model version involves specifying how the model is sourced, served, and managed. This guide explains each section of the model version configuration interface.
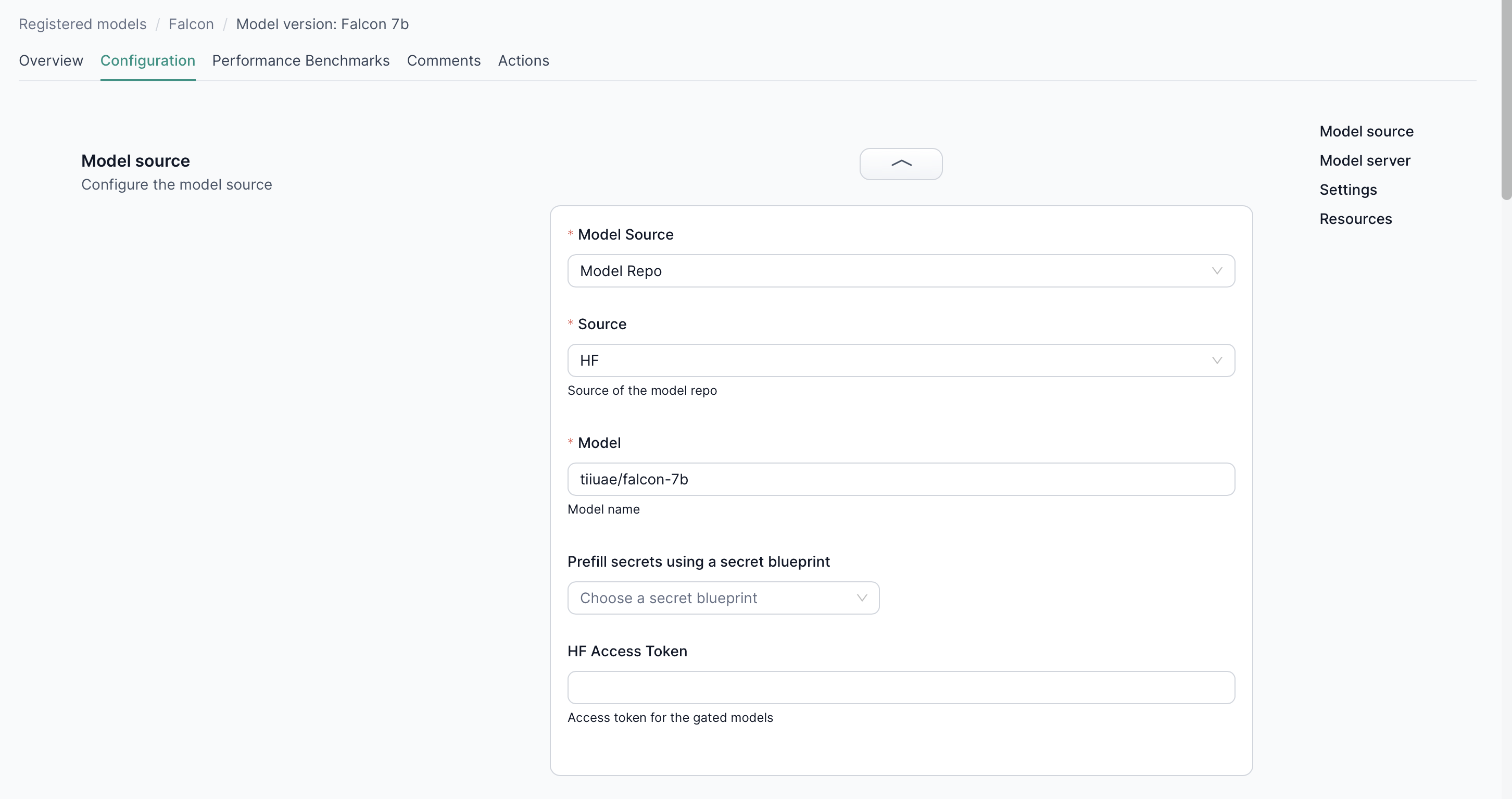
1. Model Source
Identify where your model originates to ensure correct deployment:
-
Tracked
- Use a model tracked within OICM’s tracking module.
- Select the specific run associated with the model.
-
Model Repo (Transformer-based models)
- Huggingface – Provide the Huggingface model ID.
- S3 Bucket – Specify bucket/folder details and your S3 credentials.
-
External
- Deploy a model bundle. Refer to Model Bundle Documentation for details.
-
Docker Image
- Use a custom Docker image. See Docker Image Documentation.
2. Model Server
Select a serving framework suited to your model type and deployment needs:
-
MLFLOW
- Default choice for classical ML models.
- Handles a variety of frameworks (scikit-learn, XGBoost, etc.).
-
TGI (Text Generation Inference)
- Rust, Python, and gRPC server designed for text generation models.
- Used at HuggingFace for high-performance text generation.
-
vLLM
- Python library with precompiled C++/CUDA binaries for text generation.
- Efficient deployment for supported text generation models.
-
OI Serve (Open Innovation Serve)
- Built on top of RayServe to deploy various LLM pipelines.
- Supports text generation, sequence classification, translation, Automatic Speech Recognition (ASR), Text To Speech (TTS), and text-to-image.
- Performance may differ from specialized servers like TGI or vLLM.
-
Text-Embedding-Inference (TEI)
- Toolkit for deploying and serving open-source text embeddings and sequence classification models.
- Handles embeddings, re-ranking, and classification.
Each option requires specific parameters (e.g., port, environment variables), which you’ll specify during configuration.
3. General Settings
Define basic operational properties:
- Name – Give the model version a descriptive name.
- Tags – Add tags for easier organization and discovery.
- Number of Replicas – Determine how many instances of the model should run in parallel.
4. Resources
Allocate compute resources for optimal performance:
- GPU – Assign GPU resources if needed for inference.
- Memory – Set memory limits.
- CPU – Define CPU cores or shares for the model.
- Storage – Specify storage requirements for artifacts or logs.
5. Chat Templates
If deploying an LLM with chat inference, add a custom chat template if your model family isn’t supported by default. The OI platform natively supports:
- LLAMA 2, LLAMA 3
- Falcon
- Yi
- Mistral
- Aya-23
If you cannot provide a chat template, you can still use completion inference.
Note: A chat template must be valid Jinja containing variables
messagesandadd_generation_prompt.
Example chat template for CohereForAI/aya-23:
<BOS_TOKEN>
{% if messages[0]['role'] == 'system' %}
{% set loop_messages = messages[1:] %}
{% set system_message = messages[0]['content'] %}
{% else %}
{% set loop_messages = messages %}
{% set system_message = false %}
{% endif %}
{% if system_message != false %}
{{ '<|START_OF_TURN_TOKEN|><|SYSTEM_TOKEN|>' + system_message + '<|END_OF_TURN_TOKEN|>' }}
{% endif %}
{% for message in loop_messages %}
{% if (message['role'] == 'user') != (loop.index0 % 2 == 0) %}
{{ raise_exception('Conversation roles must alternate user/assistant/user/assistant/...') }}
{% endif %}
{% set content = message['content'] %}
{% if message['role'] == 'user' %}
{{ '<|START_OF_TURN_TOKEN|><|USER_TOKEN|>' + content.strip() + '<|END_OF_TURN_TOKEN|>' }}
{% elif message['role'] == 'assistant' %}
{{ '<|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>' + content.strip() + '<|END_OF_TURN_TOKEN|>' }}
{% endif %}
{% endfor %}
{% if add_generation_prompt %}
{{ '<|START_OF_TURN_TOKEN|><|CHATBOT_TOKEN|>' }}
{% endif %}
Click "Get Chat Template" to fetch a pre-built template for supported Huggingface models using your secrets from the model version form.
Next Steps
- Registered Models & Versions – Organize multiple versions of your models.
- Model Bundle Documentation – Learn about deploying external model bundles.
- Docker Image Documentation – Explore building custom Docker images for specialized use cases.