User Interface
Deployments UI
Accessing Model Deployments
- Navigate to the Model Deployments section from the main platform menu
- The dashboard displays your existing deployments with their status
- Use the search functionality to find specific deployments
Creating a New Deployment
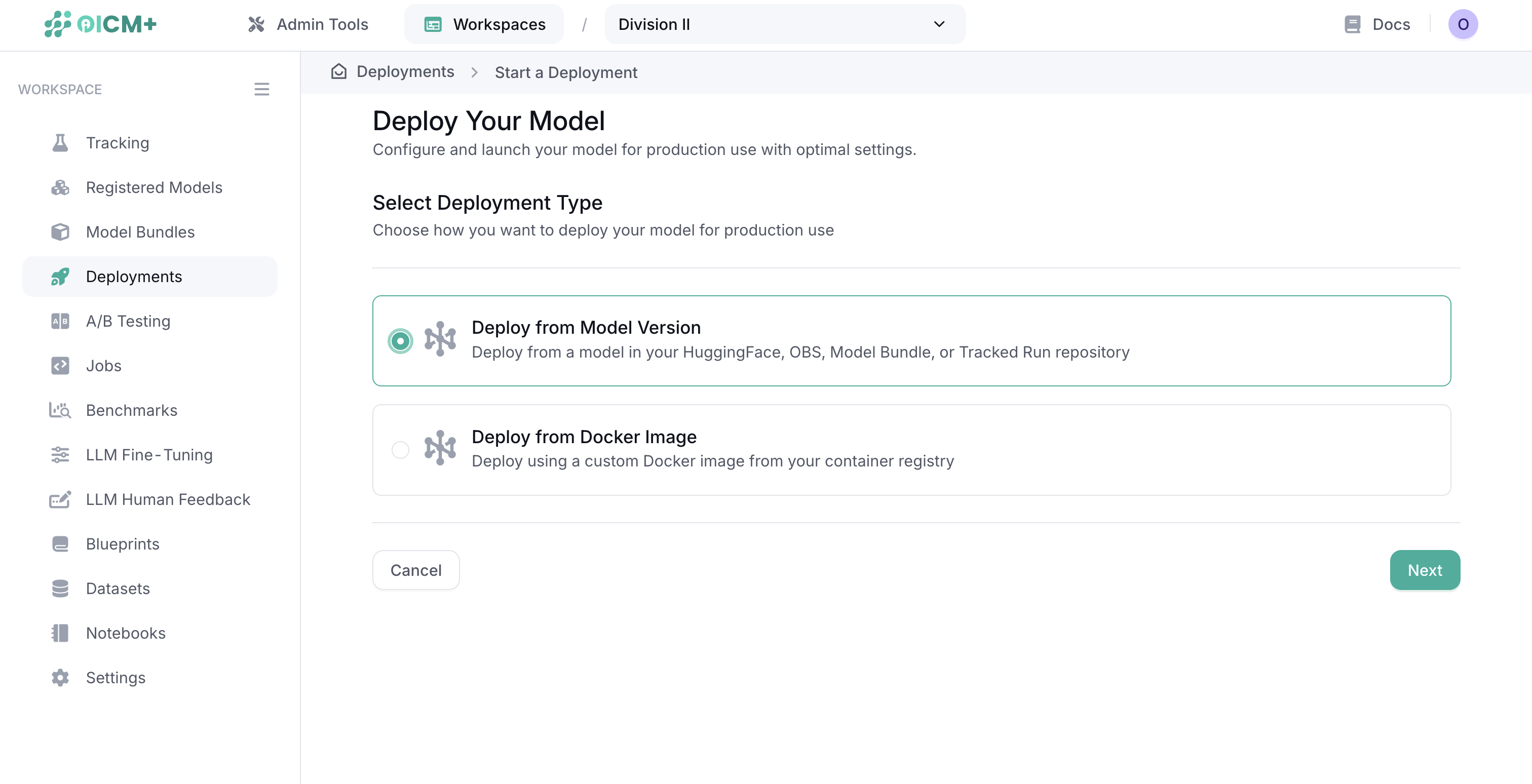
You can deploy either registered models from the Model Registry or custom Docker images.
Step 1: Model Selection
- Click the "Create New Deployment" button
- Choose your deployment source:
- Registered Model: Deploy a model from the Model Registry
- Custom Docker Image: Deploy your own containerized model
Deploying a Registered Model
When deploying from the Model Registry, follow these steps:
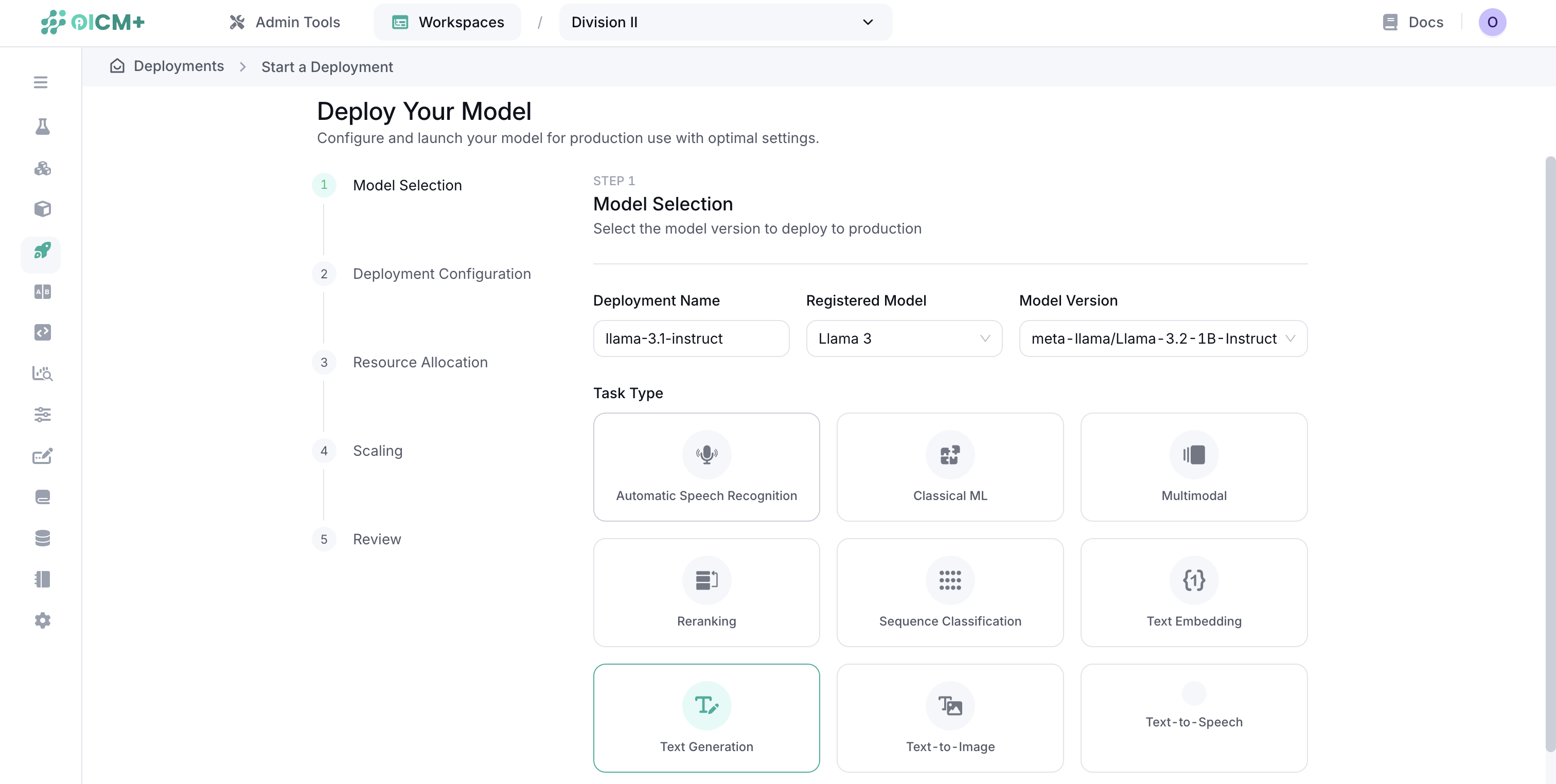
Step 1: Model Selection
- Enter a unique deployment name
- Select a registered model from the dropdown
- Select a specific model version from the dropdown
- Choose the appropriate task type for your model:
- Text Generation (LLMs)
- Text-to-Image
- Text-to-Speech
- Automatic Speech Recognition (ASR)
- Classical ML
- And others
Note: For guidance on task types, refer to the Hugging Face model categories which provides a comprehensive list of tasks and their purposes.
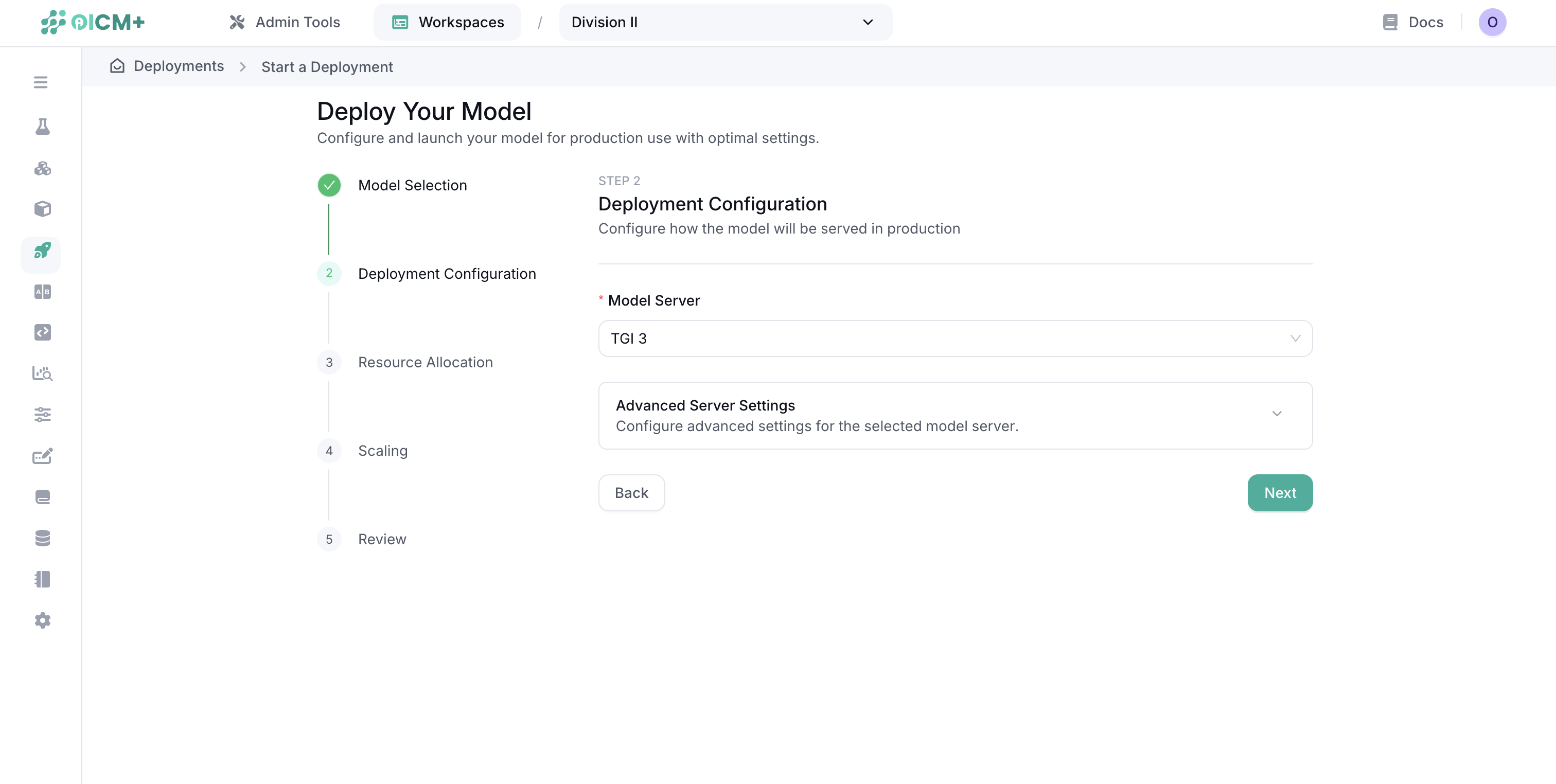
Step 2: Deployment Configuration
Select a model serving framework based on your requirements:
- TGI 2: Text Generation Inference v2
- TGI 3: Text Generation Inference v3
- vLLM: High-throughput and memory-efficient inference
- SGLang: Structured Generation Language
- Ray Serve: Scalable model serving framework
- OI_Serve: Our proprietary serving framework
- Text_embedding_inference: Specialized for embedding models
Note: Each framework has its own set of configuration options. Default configurations are provided for all frameworks, but you can customize them as needed.
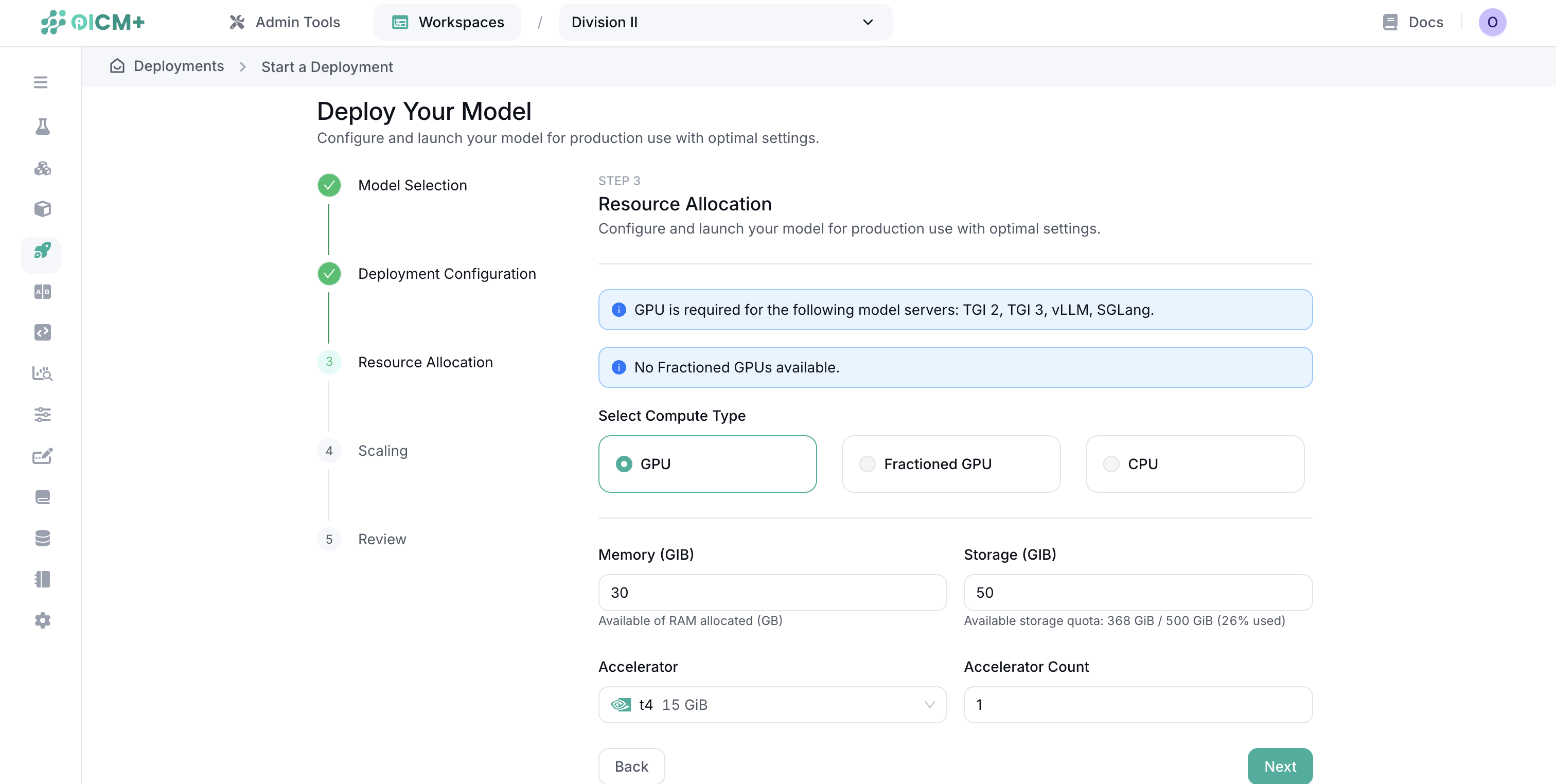
Step 3: Resource Allocation
Configure the computing resources for each deployment instance:
- Compute Type:
- Full GPUs
- Fractional GPUs
- CPUs
- Memory (RAM): Amount of memory allocated to each instance
- Storage: Disk space for model artifacts and runtime data
- Accelerator Type: GPU model (if applicable)
- Accelerator Count: Number of GPUs per instance
- CPU Count: Number of CPU cores per instance
Important: Resources specified here are for a single deployment instance. The total resources consumed will be multiplied by the number of replicas configured in the next step.
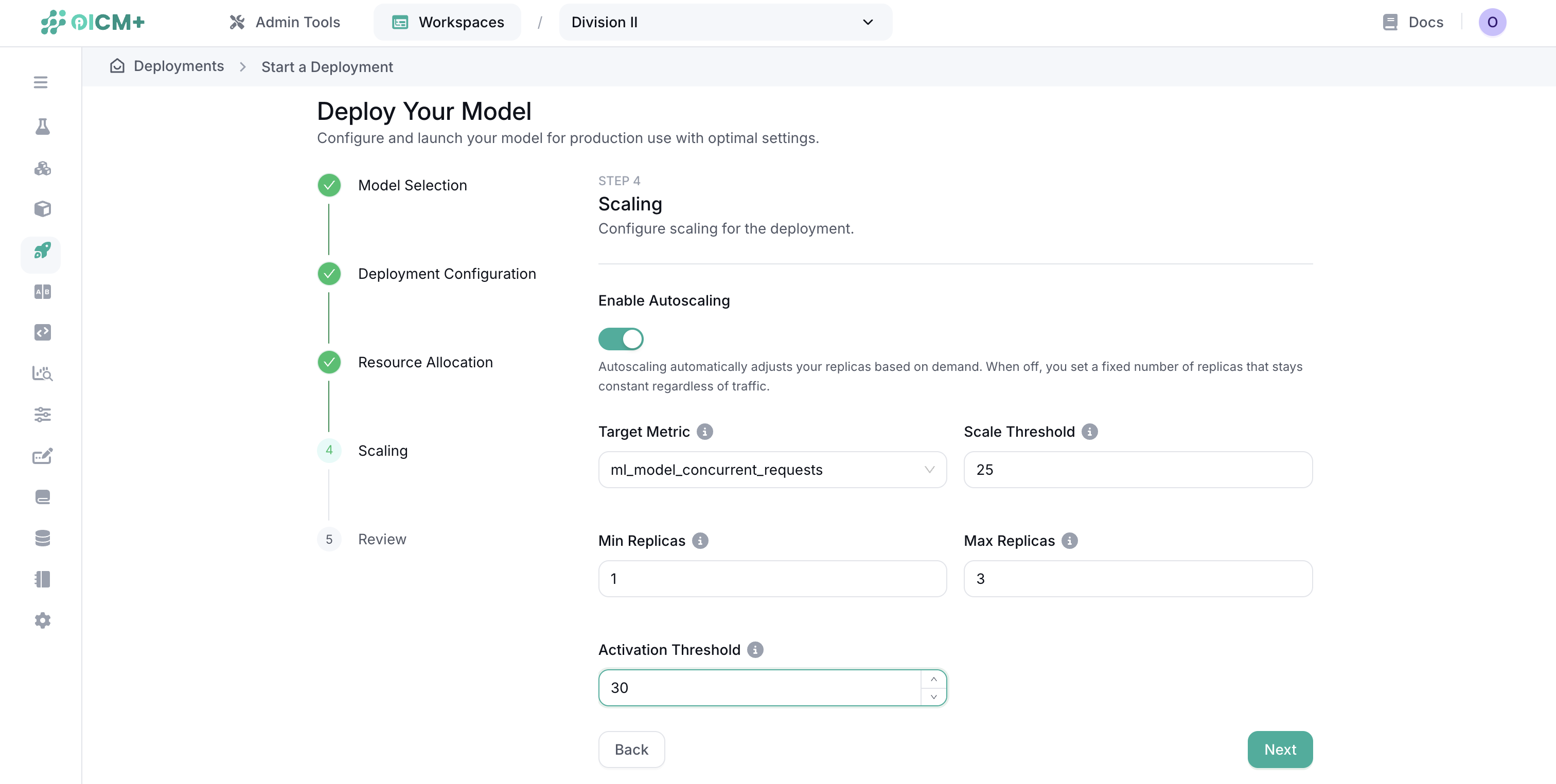
Step 4: Scaling Configuration
- Toggle "Enable Autoscaling" on or off
- For fixed scaling (autoscaling disabled):
- Set the number of replicas to maintain at all times
- For autoscaling (enabled):
- Target Metric: The metric used to trigger scaling (default: ml_model_concurrent_requests)
- Scale Threshold: The value of the target metric that triggers scaling
- Min Replicas: Minimum number of instances to maintain regardless of load
- Max Replicas: Maximum number of instances allowed during peak load
- Activation Threshold: The threshold that must be exceeded to trigger a scaling event
Autoscaling Example
Consider an LLM deployment with the following configuration:
- Target Metric: ml_model_concurrent_requests
- Scale Threshold: 5
- Min Replicas: 1
- Max Replicas: 10
- Activation Threshold: 6
In this scenario:
- The deployment starts with one replica
- When the number of concurrent requests exceeds 6, the platform triggers the scale-up
- New replicas are added until each instance handles approximately 5 concurrent requests
- During periods of low activity, replicas are gradually removed until reaching the minimum (1)
- The system maintains between 1 and 10 replicas depending on the load
This approach ensures efficient resource utilization while maintaining responsive service.
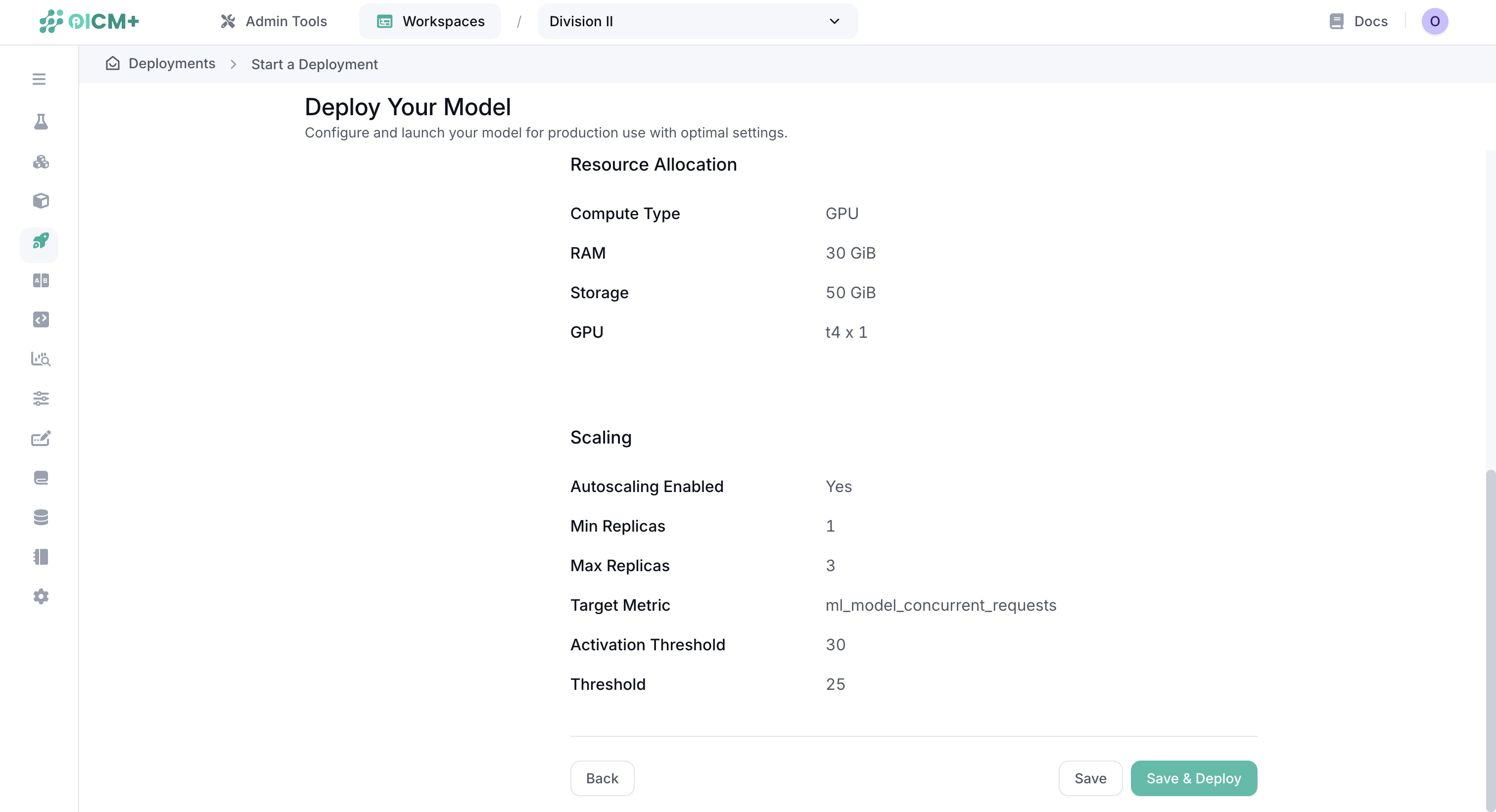
Step 5: Review and Deploy
The final step shows a summary of your deployment configuration:
- Review all settings
- Choose one of the deployment options:
- Save: Store the configuration without starting the deployment
- Save & Deploy: Create and immediately start the deployment
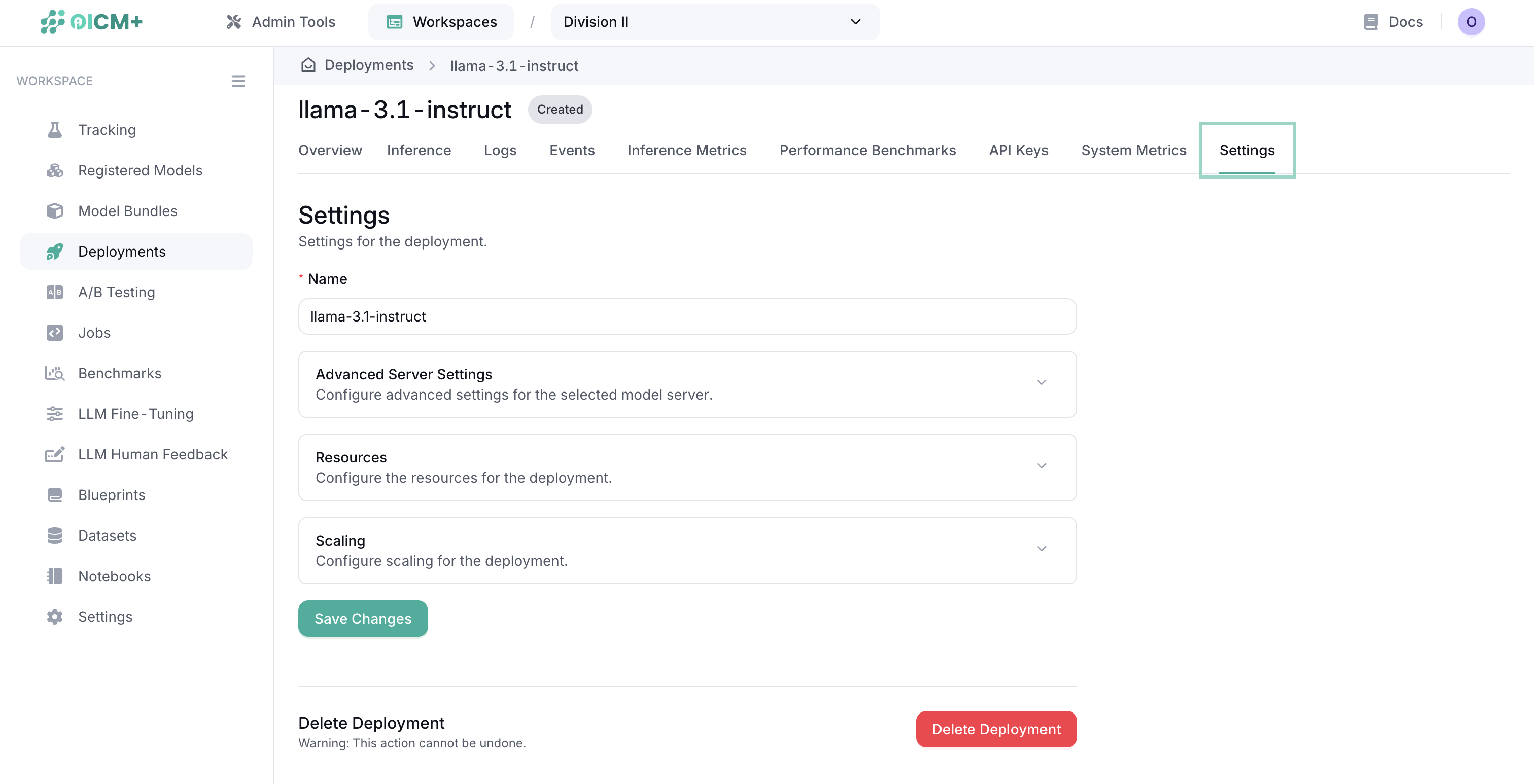
Managing Deployments
Once created, you can manage your deployments through the Deployments dashboard:
- Monitor the status of active deployments
- Start, stop, or delete deployments
- View performance metrics and logs
- Update deployment configurations
Best Practices
- Resource Optimization: Start with modest resources and scale based on actual performance
- Autoscaling: Configure appropriate thresholds to balance performance and cost
- Monitoring: Regularly review deployment metrics to identify optimization opportunities