Job Management UI
The Jobs section of the OICM+ platform allows you to create, monitor, and manage jobs that consume computing resources for tasks like machine learning model training.
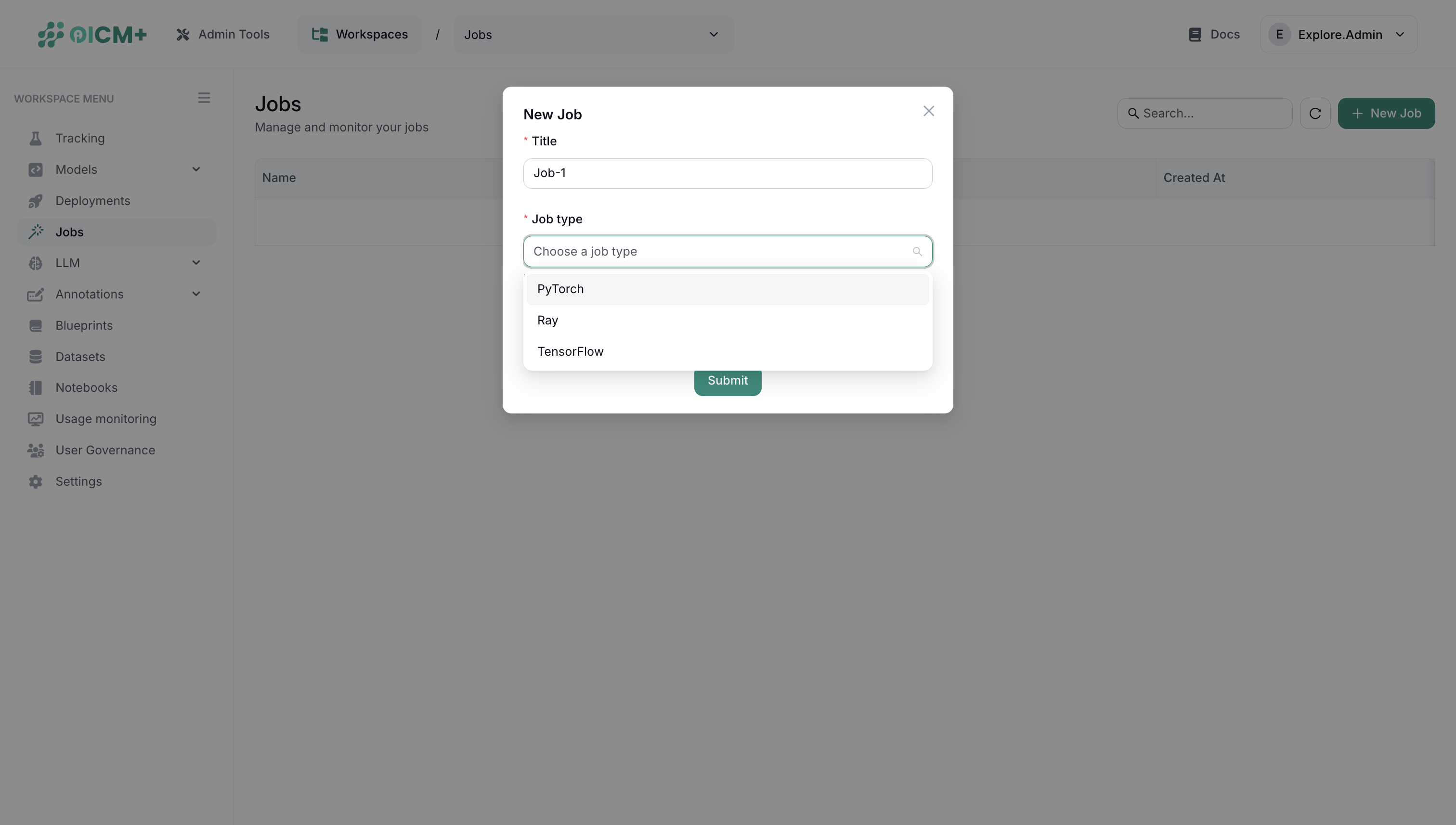
1. Initiating a New Job
- Navigate to the Jobs section.
- Create a new job by clicking + New Job.
- Fill in the form:
- Title – Descriptive name of your job.
- Job Type – Choose the framework (e.g., PyTorch, Ray, TensorFlow).
- Tags – Add optional labels for organization and filtering.
Once created, your job appears in the Jobs list alongside existing entries.
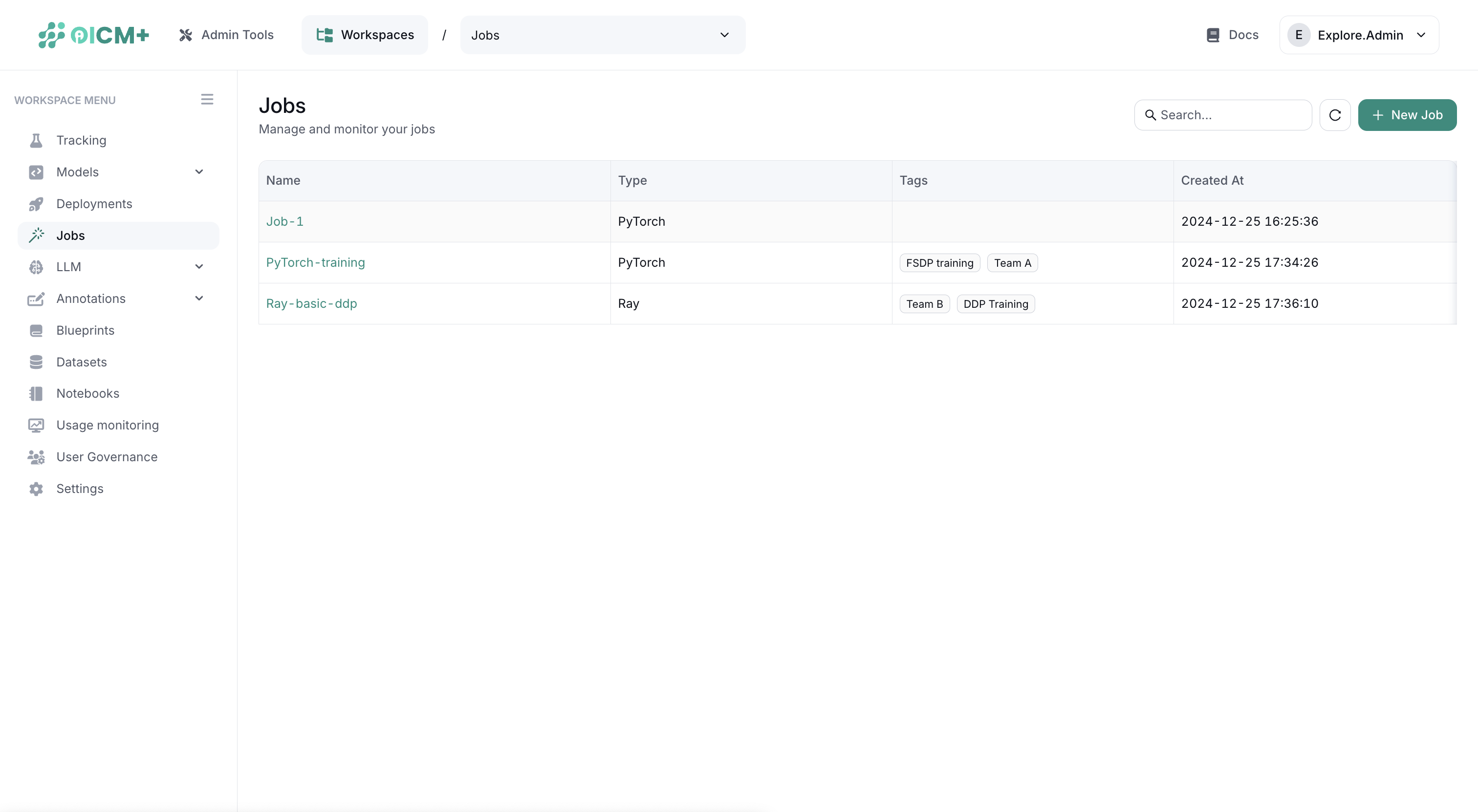
2. Job-Specific Page
Click a job in the list to view its dedicated interface, featuring multiple tabs for detailed management:
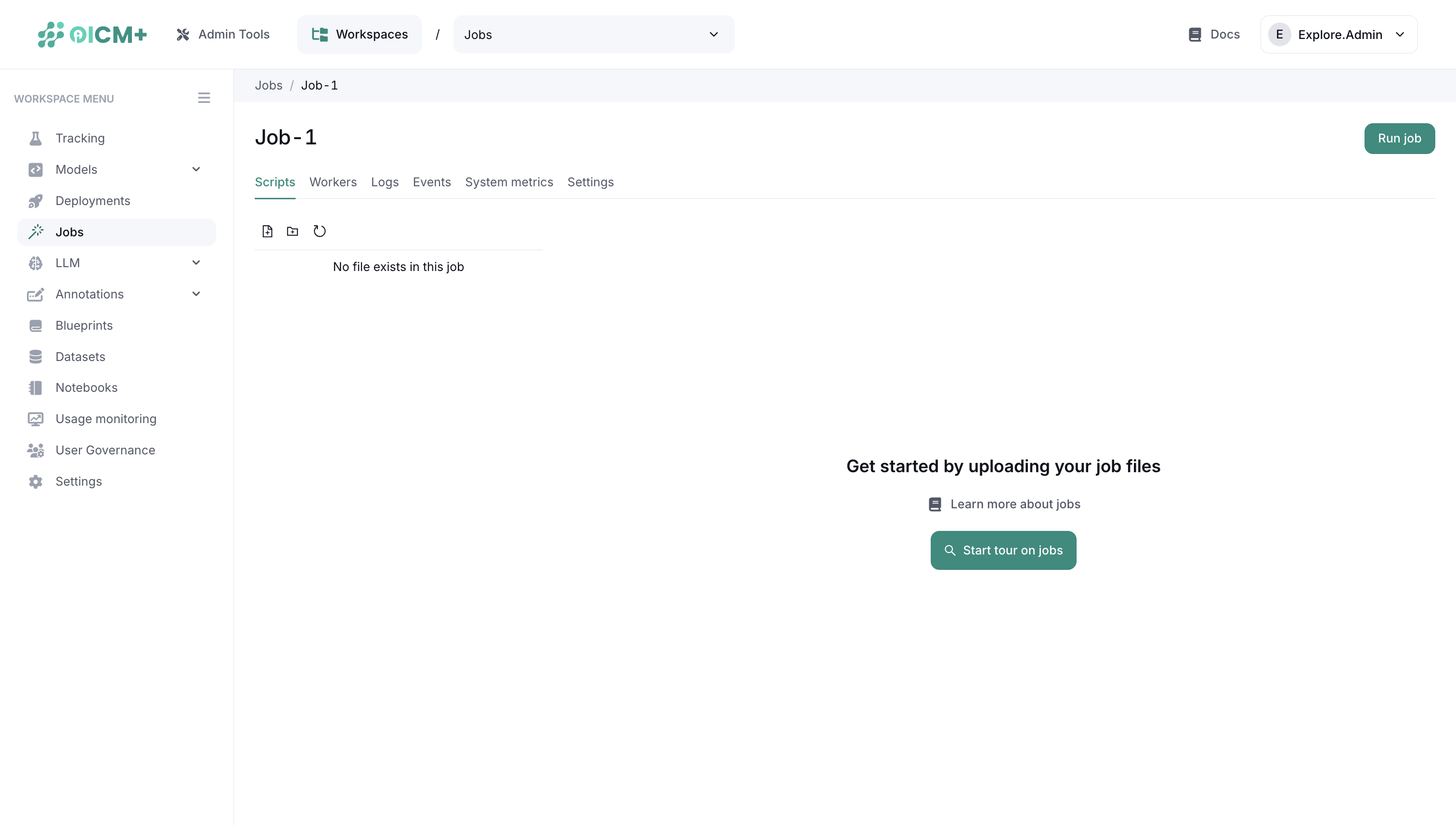
2.1 Scripts
- Upload Options – Single file or directory upload.
- Edit Files – Make changes directly in the UI.
- Delete & Refresh – Remove files or refresh the file list.
Note: For multiple files, name your main script
main.pyand config fileconfig.yamlto help the system identify primary execution files.
2.2 Workers
- Compute Units – View all allocated workers.
- Status & Resources – Track each worker’s resource usage and allocation.
- Detailed Specs – Inspect hardware configuration and specifications.
2.3 Logs
- Real-Time Output – Monitor console logs for each worker.
- Worker Dropdown – Select a worker to see its specific logs.
- Live Updates – Follow the execution flow in real time.
2.4 Events
- Chronological Timeline – Capture all job-related events in order.
- Notifications – Highlight errors, warnings, or major transitions.
- Diagnostics – Help you pinpoint issues and track job states.
2.5 System Metrics
- GPU Indicators – Core utilization, temperature, memory usage.
- Real-Time & Historical – Interactive graphs for current or past performance.
- Hardware Usage – Encoder/decoder utilization and more.
2.6 Settings
- Update Configuration – Modify job title, type, and tags.
- Delete Job – Remove the entire job from the platform when no longer needed.
3. Monitoring Job Performance
Use tabs in combination for a full picture:
- Events + System Metrics – Correlate timeline events with resource usage to detect performance drops.
- Workers + System Metrics – Identify bottlenecks by comparing worker status with CPU/GPU usage.
- Logs + Events – Debug issues by viewing runtime output alongside relevant warnings or errors.
4. Best Practices
- Assign Resources Properly – Check the Workers tab to ensure correct CPU/GPU allocations.
- Track System Metrics – Optimize usage by monitoring GPU memory, temperature, and utilization.
- Review Events – Understand the lifecycle and troubleshoot issues quickly.
- Use Logs – Drill down into specific worker logs for real-time debugging.
- Tag Jobs – Organize and filter for better discoverability, especially in large teams.
Next Steps
- Jobs Overview – Explore the underlying concepts of job management.
- Jobs Examples – Learn about writing scripts for advanced job configurations.
- Resource Allocation – Manage CPU/GPU resources across multiple jobs effectively.