Benchmarks UI
When you select Benchmarks from the sidebar, you’ll see an overview of benchmark packages, which are simply collections of individual benchmarks.
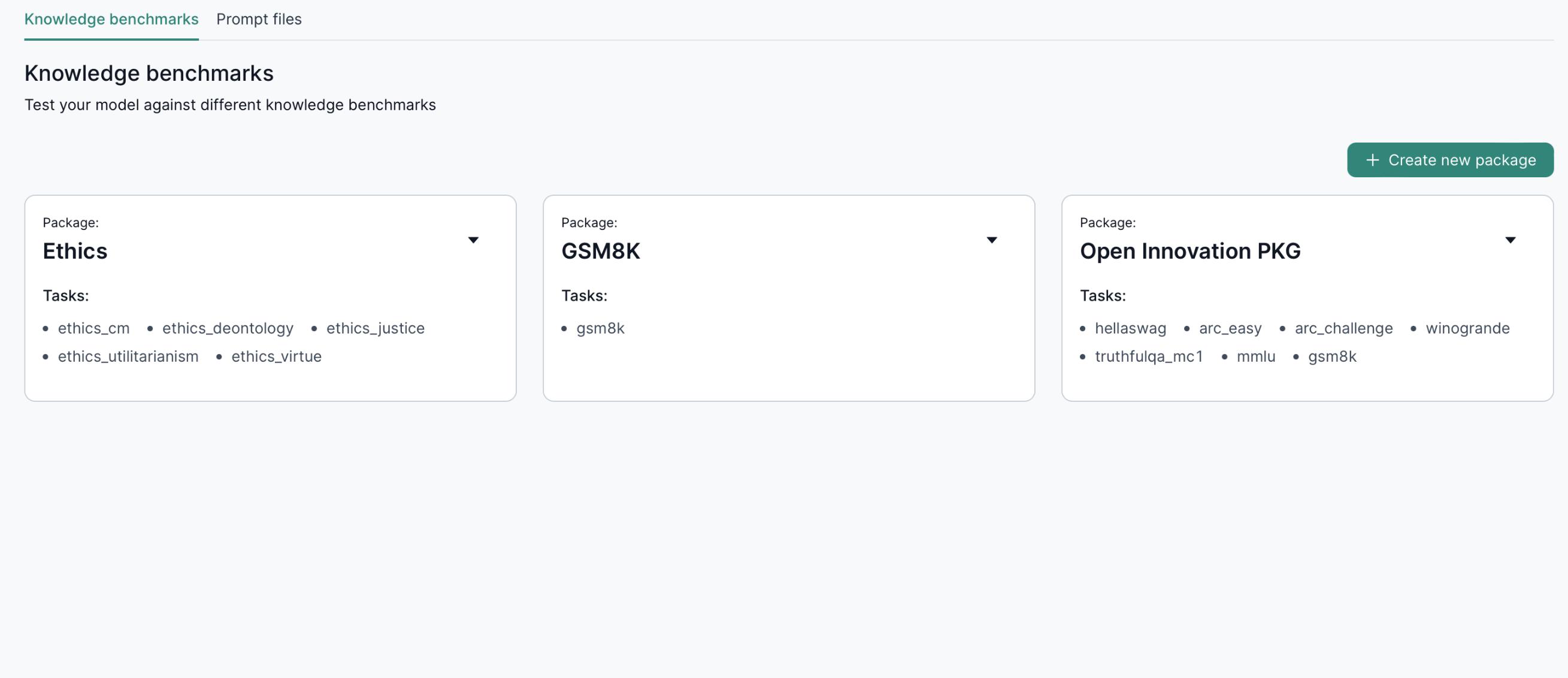
1. Creating a New Benchmark Package
- Click Create new package.
- Name your package.
- Specify the tasks you want to evaluate.
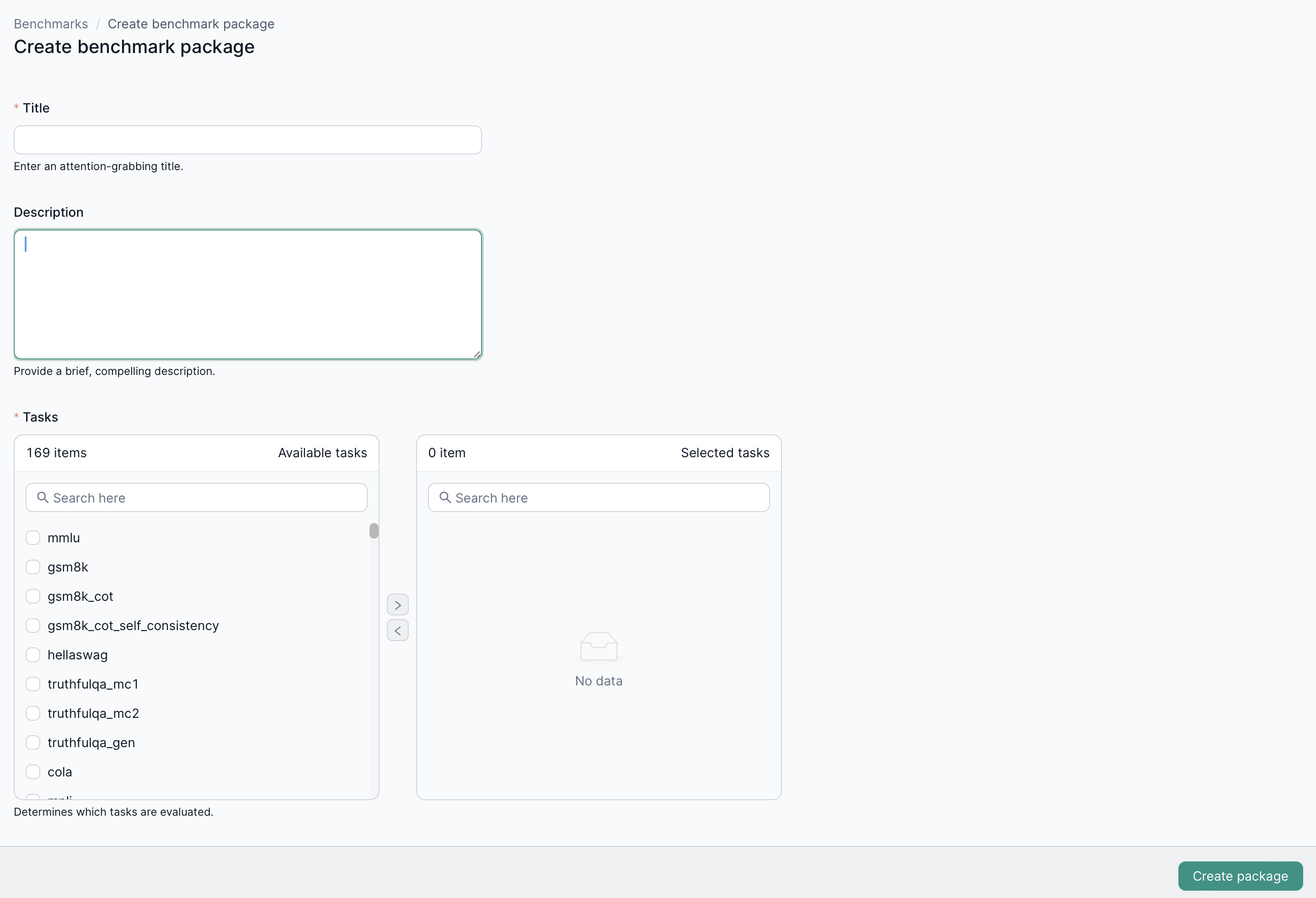
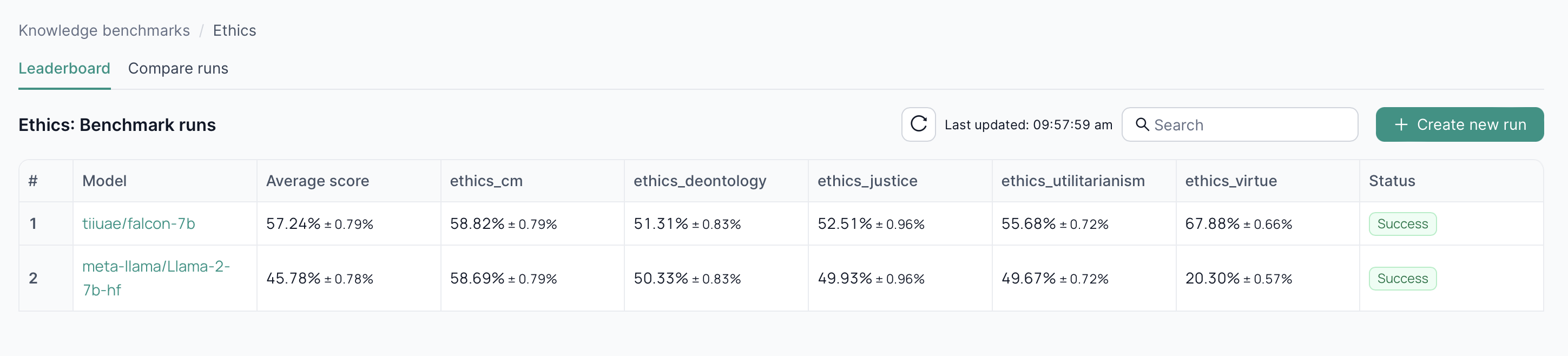
2. Benchmark Runs
After choosing a package, you’ll see a list of benchmark runs for that package.
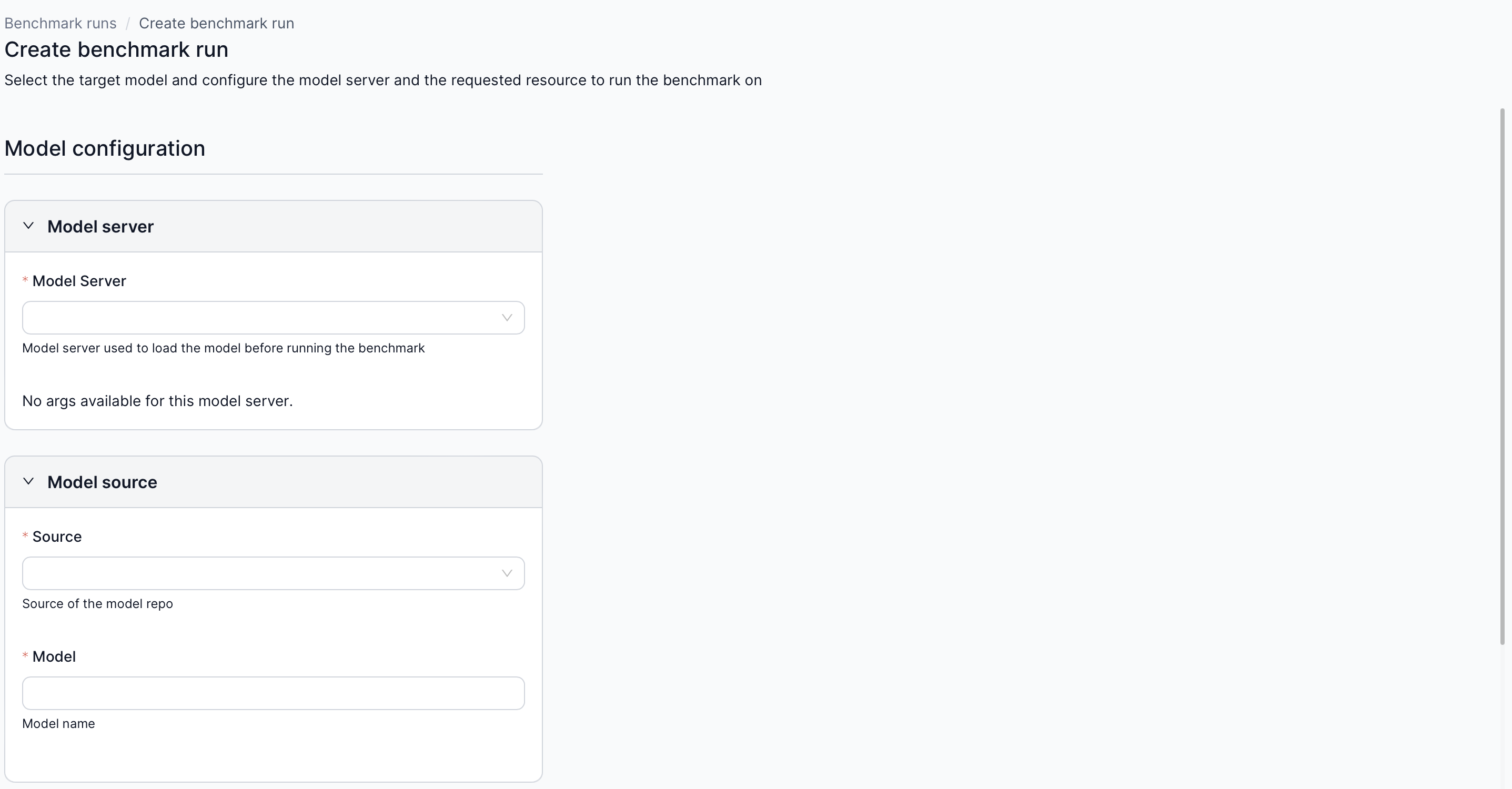
2.1 Create a New Run
- Click Create new run.
- Select the model and resource allocations needed.
- Confirm to start the benchmark.
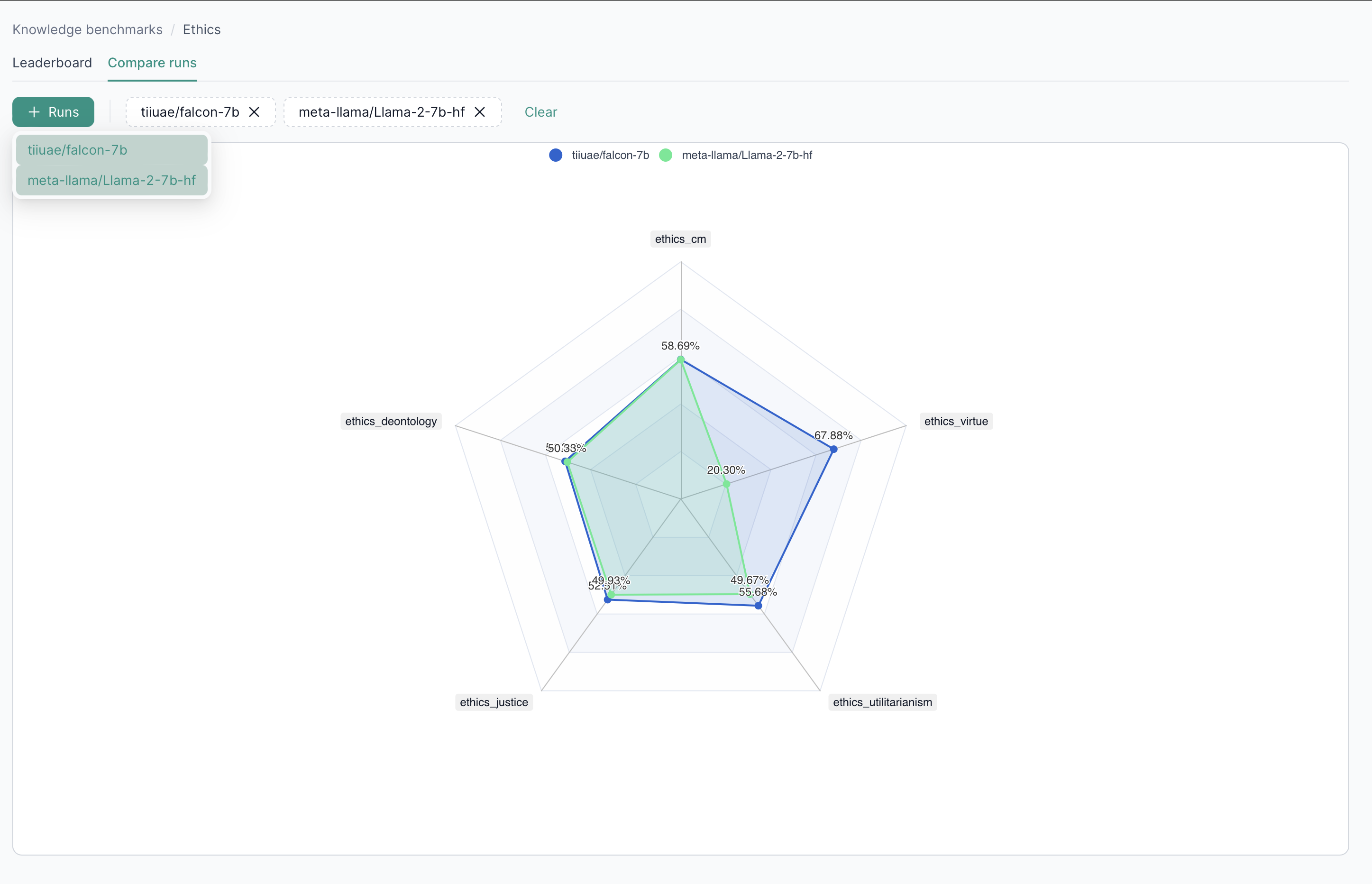
3. Compare Runs
In the Compare runs tab, pick multiple runs to analyze side by side.
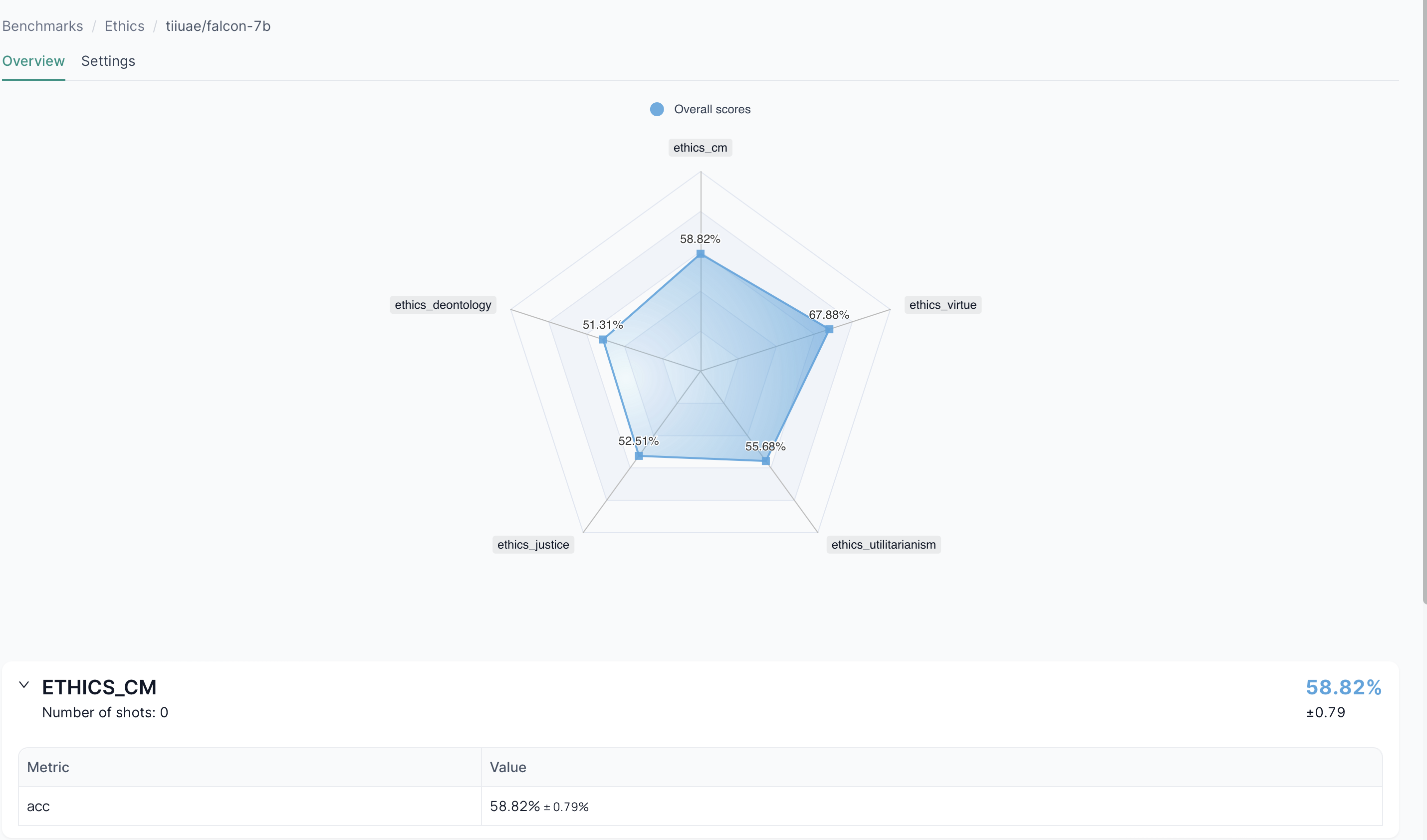
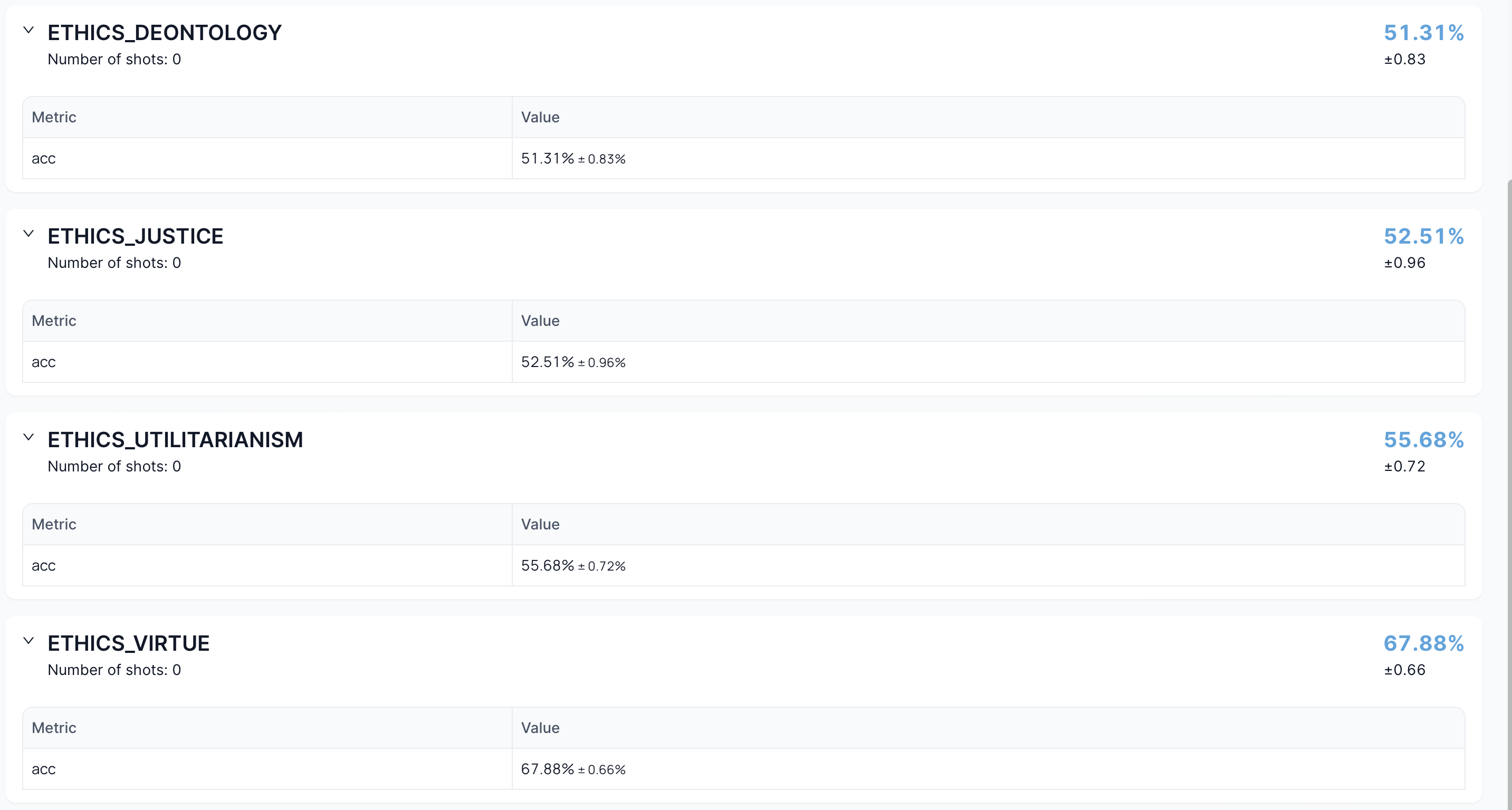
4. Benchmark Run Overview
Selecting a specific run opens a detailed view with:
- Execution details
- Logs
- Metrics
- Task configurations
5. Benchmark Run Settings
Navigate to the Settings tab of a run to delete it or modify related configurations.

6. Prompt Files
Under Benchmarks > Prompt files, you’ll find a list of existing prompt files used in benchmarking.
6.1 Upload Prompt Files
- Click Upload files
- Select the file(s) needed for your benchmark tasks
7. Custom Tasks
The Custom tasks tab lets you define user-created benchmark tasks. They can be combined with existing platform tasks in a single package.
7.1 Creating a User-Defined Task
- Click Create new task
- Complete the form fields:
- General – Task name, dataset, metrics, etc.
Task name: the name of the task. Must be unique.Description: the task description.Dataset: the dataset file to use for the task. Supports CSV and json.Metrics: list of metrics to use to evaluate the task.Task Output Type: the type of the task.generate_until: generate text until the EOS token is reached.loglikelihood: return the loglikelihood probability of generating a piece of text given a certain input.loglikelihood_rolling: return the loglikelihood probability of generating a piece of text.multiple_choice: choose one of the provided options.
- Prompting – Define how prompts and answers are formatted.
Prompt Column: Prompt to feed to the LLM. Can be either a column in the dataset or a template.Answer Column: Expected answer. Can be either a column in the dataset or a template.Possible Choices: Possible choices when using the multiple_choice task output type.Fixed Choices: Specifies whether the same set of choices (Possible Choices) is used for every prompt.
- Few-Shots – Include example-based configurations.
Number of few-shots: number of few-shots examples to add to the prompt.Few-shots description: a string prepended to the few-shots. Can be either a fixed string or a template.Few-shots delimiter: String to insert between the few-shots. Default is a blank line "\n\n".
- Advanced – Repeat runs, delimiters, etc.
Repeat Runs: number of times each sample is fed to the LLM.Target delimiter: string added between question and answer prompt. Default is a single whitespace " ".
- General – Task name, dataset, metrics, etc.
Prompt Examples
-
Basic Prompt
If your dataset has columnsquestionandanswer, set Prompt Column toquestionand Answer Column toanswer. -
Template Prompt
Use placeholders like{{passage}}or{{question}}in your prompt field. -
Multiple Choice
Provide a list of columns for possible choices, and mark the correct answer column.
We can then configure our task with:
- Prompt Column: question
- Possible Choices:
-distractor1
-distractor2
-correct - Answer Column: correct
Next Steps
- Knowledge Benchmarking Overview – Learn about the broader theory and features.
- LLM Fine-Tuning UI – Adapt your models before benchmarking them.
- Inference UI – See how models perform in real-world testing scenarios.